الفرق بين المترجم والمفسر : Compiler vs Interpreter
مقدمة حول الفروق الجوهرية بين المترجم والمفسّر في عالم البرمجة
يُعَدُّ فهم الفروق بين المترجم (Compiler) والمفسّر (Interpreter) من القضايا المحورية في علوم الحاسوب وتطوير البرمجيات، إذ يرتبط اختيار النهج المناسب بآليات تنفيذ الشفرة المصدرية وبرمجة الأنظمة عالية التعقيد. يتناول هذا المقال التحليلي الموسع التفسيرات التقنية للمفاهيم الأساسية لكلٍّ من المترجم والمفسّر، ويستعرض تاريخهما وتطوّرهما، إضافة إلى التحولات التي طرأت على عملية ترجمة الشفرة وتنفيذها على مر العقود الماضية. كما سيتطرق المقال إلى العلاقة بين الأداء والموارد واستخدامات كل تقنية في التطبيقات المختلفة، فضلاً عن ذكر تطبيقات عملية في لغات البرمجة المشهورة وآليات تطويرها.
يشتمل هذا المقال على تحليل عميق للآليات الكامنة وراء كل من عملية الترجمة والتفسير، ويفصّل الأجزاء المشتركة بينهما مع تسليط الضوء على أوجه الاختلاف الأساسية من حيث زمن التنفيذ، واستهلاك الذاكرة، وآليات اكتشاف الأخطاء ومعالجتها، ومستوى التحكم في العتاد. بالإضافة إلى ذلك، سيتم إبراز نماذج لغات البرمجة التي تتبنى أحد النهجين أو المزج بينهما (مثل لغة جافا التي تجمع بين المفهومين عبر الآلة الافتراضية وآلية التجميع الجزئي Just-In-Time). وحرصاً على الإحاطة الشاملة، سيتطرق المقال إلى بعض النقاط الثانوية التي قد تكون محدِّداً في اعتماد إحدى العمليتين في المشاريع البرمجية الكبرى أو التطبيقات التي تتطلّب أداءً فائقاً.



لمحة تاريخية عن نشأة المترجمات والمفسّرات
عند العودة إلى تاريخ علوم الحاسوب، يظهر بوضوح أنّ الحاجة إلى تسهيل عملية البرمجة وتنفيذ التعليمات ظهرت في وقت مبكر منذ اختراع الحواسيب الإلكترونية. فقد كانت البرمجة المبكرة تُجرى باستخدام لغة الآلة (Machine Language) فقط، والتي تتألف من سلسلة أرقام ثنائية (0 و1)، مما جعل التطوير أمرًا معقدًا ويستغرق زمنًا طويلاً. ومع تطوّر العتاد بدأ العلماء في ابتكار لغات التجميع (Assembly Languages)، لتجعل عملية كتابة الأوامر أقرب إلى المنطق البشري منها إلى لغة الآلة الصِرفة.
تزامن هذا التطور في لغات البرمجة مع ظهور أدوات تُحسّن من سير عملية تنفيذ البرامج، إذ إن لغات المستوى العالي (High-Level Languages) مثل الفورتران (FORTRAN)، والكوبول (COBOL)، والليسب (LISP) وغيرها، لم تكن تستطيع العمل مباشرة على العتاد (المعالج والذاكرة) دون وساطة تُترجم أو تفسّر التعليمات إلى أوامر قابلة للتنفيذ. ومن هنا بدأت حقبة جديدة من التقنيات تُعرف بالمترجمات والمفسّرات.
يمكن القول إنّ المفسّرات التاريخية ظهرت في مراحل مبكرة لمواكبة الحاجة إلى فهم سريع للتعليمات البرمجية في لغات الذكاء الاصطناعي الناشئة، كما حدث في لغة الليسب (LISP) في نهاية الخمسينات وبداية الستينات من القرن العشرين. أما المترجمات فقد ازدهرت مع اللغات الرياضية والعلمية مثل الفورتران التي ظهرت لأول مرة في منتصف الخمسينات تقريبًا. وقد استمر التطوّر بالتوازي بين التقنيات المختلفة، فظهرت لغات وأدوات جديدة أعادت صياغة مفهوم الترجمة والتفسير، وصولاً إلى عصرنا الحالي الذي نرى فيه وجود مزيج بين الاثنين في بعض اللغات الحديثة مثل جافا (Java) وسي شارب (C#).
تعريفات أساسية للمترجم والمفسّر
ما هو المترجم؟
المترجم (Compiler) هو برنامج يقوم بتحويل الشفرة المصدرية المكتوبة بلغة برمجة عالية المستوى إلى شفرة آلة (Machine Code) أو إلى صيغة وسيطة (Intermediate Representation) يمكن تنفيذها مباشرة من قِبل الحاسوب. يُجرى هذا التحويل على مراحل تحليلية متعاقبة تشمل المسح (Lexical Analysis)، والتحليل النحوي (Syntax Analysis)، والتحليل الدلالي (Semantic Analysis)، ثم التوليد الأمثل للشفرة (Code Generation and Optimization).
غالبًا ما تتم عملية التحويل كاملة في مرحلة مسبقة على تشغيل البرنامج، وهذا يعني أن البرنامج يُترجَم بالكامل مرة واحدة قبل بدء التنفيذ (أو في بعض الأحيان يتم توليد ملف ثنائي مستقل Executable). ونتيجة لذلك، تُصبح عملية التنفيذ لاحقًا أسرع لأنه ليس هناك حاجة لإعادة ترجمة الأوامر في كل مرة تتم فيها إعادة التنفيذ. ومع ذلك، يستغرق بناء البرنامج لأول مرة مزيدًا من الوقت لعملية الترجمة ذاتها. إضافة إلى ذلك، يفرض هذا النموذج آليات معينة في تتبع الأخطاء والتصحيح.
ما هو المفسّر؟
المفسّر (Interpreter) هو برنامج يقرأ الشفرة المصدرية سطرًا بسطر (أو تعليمةً تلو الأخرى)، ويفهمها ويفسّرها ثم ينفّذها بشكل مباشر دون توليد ملف ثنائي منفصل. يعدّ هذا النوع من التنفيذ تفاعليًا، إذ يمكن تعديل التعليمات وتجربتها على الفور، كما يحدث في بعض لغات السكربت (Scripting Languages) مثل البايثون (Python) والروبي (Ruby).
بالرغم من سهولة بناء أنظمة تعتمد على المفسّر، إلا أن الأداء قد يكون أبطأ عند التنفيذ مقارنة بالمترجم، لأن الشفرة تُحلَّل وتُنفَّذ مرة واحدة في كل دورة تشغيل. إضافة إلى ذلك، يتيح هذا المفهوم ميزة التفاعل الفوري مع المترجم (REPL: Read-Eval-Print Loop) مما يُعدّ مفيدًا في عمليات التجربة السريعة والبرمجة التفاعلية.
مراحل عمل المترجم
تتكون عملية الترجمة النموذجية في المترجم من عدة مراحل متتالية، يُطلق عليها في الغالب Front-End وMiddle-End وBack-End. في ما يلي تفصيل للمراحل العامة:
التحليل المعجمي (Lexical Analysis)
يُعدّ التحليل المعجمي أول خطوة في بناء المترجم، حيث يُقسِّم البرنامج الشفرة المصدرية إلى وحدات أساسية تُسمى Tokens. هذه الوحدات يمكن أن تكون كلمات محجوزة (Keywords)، أو معرفات (Identifiers)، أو أرقامًا، أو رموزًا خاصة كعلامات العمليات الحسابية والمنطقية. يقوم المحلِّل المعجمي (Lexer أو Scanner) بالتأكد من مطابقة كل عنصر لغوي (Lexeme) للقواعد المقررة في بناء اللغة.
التحليل النحوي (Syntax Analysis)
في هذه المرحلة، يواجه البرنامج المحلِّل النحوي (Parser) الذي يحوّل قائمة الـTokens إلى شجرة بنائية (Parse Tree) أو شجرة تجريدية (Abstract Syntax Tree – AST). تُبيّن هذه الشجرة البنية التركيبية للتعليمات وفق القواعد النحوية للغة (Grammar). يتم فحص مدى توافق تركيبة الجمل البرمجية مع بنية اللغة، وإذا وُجد خطأ نحوي فلا يتم تجاوز المرحلة حتى يتم إصلاحه.
التحليل الدلالي (Semantic Analysis)
بعدما يتم بناء الشجرة النحوية، تأتي مرحلة التحقق من المعنى الدلالي للتعليمات. يتحقق المحلِّل الدلالي من مدى صحة العمليات والأنواع (Types) وإسنادات المتغيرات، ومن احتمال وجود أخطاء أخرى مثل استخدام متغيرات غير معرفة أو استدعاء دوال بعدد خاطئ من الوسائط. قد تُجرى في هذه المرحلة عملية تعريف الرموز (Symbol Table) وربطها بأنواعها المناسبة.
التوليد الوسيط والتحسين (Intermediate Code Generation and Optimization)
يتم تحويل الشجرة الدلالية إلى شفرة وسيطة (IR: Intermediate Representation) تمثل خطوات عامة يمكن ترجمتها إلى عدة معماريات مختلفة. يُعدّ هذا النهج مفيدًا حين يكون المترجم عابرًا للمنصات (Cross-Platform)، فيُكتب مرة واحدة مع جزئية خلفية منفصلة لكل معمارية (x86, ARM, إلخ). كما يمكن إجراء تحسينات على الشفرة الوسيطة مثل التخلص من التعليمات المكررة أو تبسيط العمليات الحسابية، مما يرفع من كفاءة الأداء.
التوليد النهائي للشفرة (Machine Code Generation)
في النهاية، تُترجَم الشفرة الوسيطة إلى شفرة الآلة المناسبة لمعمارية الهدف، مثل شفرة x86 أو ARM. قد تتضمن هذه الخطوة تحسينات إضافية (مثل تحسين استخدام المسجلات وسعة التنبؤ بالتفرّعات) لضمان أن البرنامج يعمل بكفاءة عالية عند تنفيذه على المنصة المستهدفة.
مراحل عمل المفسّر
تختلف منهجية المفسّر في تنفيذ التعليمات، فبدلاً من ترجمة كل الشفرة في مرحلة مسبقة، يعمل على تحليل وتنفيذ الأوامر بشكل متتابع أو تفاعلي. في ما يلي أبرز المراحل النموذجية:
التحليل المعجمي والنحوي الجزئي (Incremental Lexical and Syntax Analysis)
تبدأ عملية التفسير بحصول المفسّر على الأسطر البرمجية تدريجيًا، فيقوم بتحويلها إلى Tokens وفحصها نحويًا بقدر ما يلزم لاستخراج التعليمات الصالحة للتنفيذ الفوري. لا تُنشأ عادة شجرة بنائية كاملة للبرنامج بأكمله، بل تتم هذه العمليات بصفة جزئية، خصوصًا في المفسّرات البسيطة.
التقييم والتنفيذ الفوري (Immediate Evaluation)
بعد التحقق من صحة التركيب النحوي، يقوم المفسّر بتقييم التعبيرات البرمجية وتشغيلها على الفور. يحدث هذا في الغالب ضمن السياق (Environment) الذي يحتفظ بقيم المتغيرات والدوال. وإذا تم استدعاء دالة أو كتلة برمجية محددة، فيعيد المفسّر الكرة، محللًا الأوامر داخليًا ثم يعيد نتائج التنفيذ إلى بقية البرنامج.
التعامل مع الأخطاء أثناء التشغيل (Runtime Error Handling)
نظرًا لأن عملية التحليل والتنفيذ تتمان بالتوازي، فإن أي خطأ يظهر أثناء التنفيذ – سواء خطأ نحوي أو منطقي – يتم الإبلاغ عنه عند اكتشافه مباشرة. وبعض الأخطاء قد لا تُكتشف أصلًا إلا عند الوصول إلى نقطة في الشفرة يتم فيها استدعاء تعليمات غير صالحة، لأنه لا توجد آلية فحص مسبق للمجمل الكامل للبرنامج.
الاختلافات في الأداء واستهلاك الموارد
يعدّ الأداء (Performance) أحد أهم العوامل في اختيار المترجم أو المفسّر. يتميز المترجم بسرعة التنفيذ في الوقت الفعلي (Runtime) نظرًا لأن البرنامج يكون قد حُوّل مُسبقًا إلى شفرة آلة، مما يُغني عن تكرار التحليلات النحوية واللغوية أثناء التشغيل. أما المفسّر فيستلزم وقتًا إضافيًا في أثناء التنفيذ لأنه يقوم بتحليل الشفرة وتنفيذها في كل مرة.
في المقابل، قد يستخدم المفسّر ذاكرة أقل إجمالًا في بعض السيناريوهات لأنه يتعامل مع أجزاء صغيرة من الشفرة في كل مرة، ولا يحتاج إلى حفظ جميع مراحل التحويل. ومع ذلك فإن هذا الأمر متوقف على أسلوب التصميم، ولا يمكن تعميمه؛ إذ تستخدم بعض المفسّرات الحديثة هياكل بيانات أكثر تعقيدًا لإجراء التحسينات وإتاحة إمكانيات متقدمة كتصحيح الأخطاء والوصول إلى بيانات التنفيذ في الزمن الفعلي.
مرونة التطوير وصيانة البرمجيات
يتمتع المفسّر ببعض المزايا في ما يتصل بسرعة التطوير والتجريب، إذ يمكن كتابة بضعة أسطر برمجية وتنفيذها في الحال وملاحظة النتيجة وتصحيح الأخطاء فورًا. أما في الأنظمة التي تعتمد على المترجم، فيجب إعادة ترجمة البرنامج بعد كل تعديل، وقد يكون ذلك مستهلكًا للوقت في المشروعات الضخمة، بالرغم من وجود أنظمة بناء ذكية تكتشف فقط الأجزاء المعدَّلة وتعيد ترجمتها.
علاوة على ذلك، فإن لغات التفسير (Interpreted Languages) تُعدّ أسهل للتعلّم من قِبل المبتدئين في بعض الأحيان، إذ لا يضطر الدارسون للتعامل مع خطوات الترجمة والتوصيل، بل يكتفون بكتابة الأوامر ومشاهدة النتيجة. وفي المقابل، يوفّر استخدام لغات الترجمة (Compiled Languages) بيئة أكثر صرامة ووضوحًا على صعيد الأخطاء النحوية واللغوية قبل التنفيذ، إضافة إلى إمكانية توزيع برامج مستقلة التنفيذ لا تحتاج إلى وجود المترجم أو المفسّر على جهاز المستخدم النهائي.
التقنيات الهجينة: الجمع بين الترجمة والتفسير
شهد عالم البرمجيات ظهور مفهوم المزج بين الترجمة والتفسير (Hybrid Model)، حيث تعتمد بعض لغات البرمجة الحديثة على عملية ترجمة مبدئية إلى شفرة وسيطة قابلة للتفسير من قِبل آلة افتراضية (Virtual Machine)؛ ثم بعد ذلك تُقدَّم تحسينات أو تُجرى عملية تجميع جزئي (JIT Compilation) أثناء runtime، ما يسمح بتحسين الأداء دون فقدان المرونة.
تُعدّ لغة جافا (Java) مثالًا نموذجيًا على هذا النهج، إذ يجري تحويل الشفرة المصدرية في البداية إلى بايت كود (Bytecode) يفهمه الآلة الافتراضية لجافا (JVM)، ثم تتولى هذه الآلة الافتراضية تفسير البايت كود أو تجميعه جزئيًا إلى شفرة آلة حسب الحاجة. ويشبه هذا نموذجًا يجمع أفضل مزايا الطريقتين: إمكانية النقل بين المنصات (باستخدام الآلة الافتراضية) مع إمكانية تحسين الأداء وقت التشغيل (بواسطة JIT Compiler).
مقارنة تفصيلية بين المترجم والمفسّر
فيما يأتي جدول يوضّح أهم أوجه الاختلاف على نحو موجز:
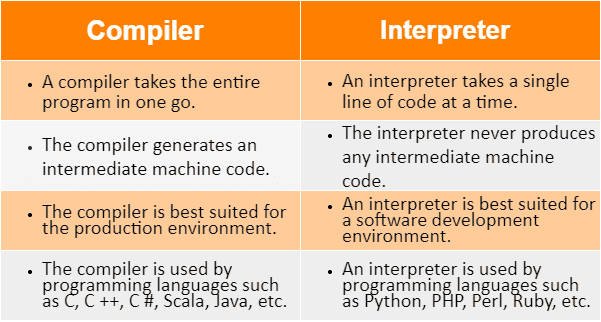
| البند | المترجم (Compiler) | المفسّر (Interpreter) |
|---|---|---|
| الآلية الأساسية | يحوّل الشفرة كاملةً إلى شفرة آلة أو صيغة أخرى قابلة للتنفيذ. | يقرأ التعليمات سطرًا بسطر أو تعليمةً بتعليمة وينفّذها فورًا. |
| سرعة التنفيذ | سريع في وقت التشغيل لأنه لا يحتاج لإعادة التحليل. | أبطأ في وقت التشغيل بسبب إعادة التحليل والتنفيذ في كل مرة. |
| مستقلّية التنفيذ | إمكانية إنتاج ملف تنفيذي مستقل. | يتطلّب وجود المفسّر لتشغيل الشفرة. |
| اكتشاف الأخطاء | تُكتشف معظم الأخطاء النحوية أثناء الترجمة قبل التشغيل. | قد لا تُكتشف الأخطاء إلا عند الوصول إلى جزء معطوب أثناء التشغيل. |
| الزمن اللازم قبل التشغيل | زمن أطول عند البناء الأوّل (الترجمة). | زمن شبه معدوم قبل التنفيذ؛ يبدأ التنفيذ فورًا. |
| التفاعل والترابط | أقل تفاعلية؛ يحتاج إعادة بناء عند تغيير الشفرة. | أكثر تفاعلية؛ يدعم الوضع التفاعلي (REPL) غالبًا. |
أمثلة على لغات البرمجة المترجمة والمفسّرة
لغات برمجة مترجمة
- C/C++: تعد من أشهر اللغات المترجمة وأكثرها استخدامًا في تطوير الأنظمة والتطبيقات ذات الأداء العالي.
- Go: لغة من تطوير جوجل تُترجم إلى ملف ثنائي مستقل، مع تركيز على البساطة والسرعة.
- Rust: لغة حديثة تتميز بالأمان والسرعة، تُترجم عادةً إلى شفرة آلة عالية الأداء.
لغات برمجة مفسّرة
- Python: لغة شائعة جدًّا في مجال الذكاء الاصطناعي وتحليل البيانات، يعمل المفسّر الخاص بها على تنفيذ الأوامر فورًا.
- Ruby: معروفة ببساطتها وأناقتها في بناء الجمل البرمجية، تُفسّر بشكل رئيسي وتستخدم في تطوير الويب.
- JavaScript: في متصفحات الويب، يُفسّر بشكل سريع (مع وجود آليات تجميع جزئي في محركات V8 وSpiderMonkey).
نماذج لغات هجينة
- Java: تعتمد على جمع الشفرة في صورة بايت كود ثم تفسيرها أو تجميعها جزئيًا عند التنفيذ.
- .NET (مثل C# وVB.NET): يتم تحويل الشفرة إلى لغة وسيطة (CIL) ثم تفسيرها أو تجميعها وقت التنفيذ.
أثر اختيار المترجم أو المفسّر على عملية التطوير
سرعة التطوير واختبار الأفكار
من النقاط المهمة التي تُؤخذ في الحسبان عند اختيار نوع اللغة، هي سرعة تكرار دورات التطوير (Development Cycle) واختبار الأفكار. قد يختار المبرمجون لغات مفسّرة لإنجاز النماذج الأولية (Prototyping) بسرعة، حيث يمكنهم إطلاق الشفرة بسهولة واختبارها وإدخال تعديلات متكررة. من جهة أخرى، تُستخدم لغات مترجمة في مراحل لاحقة لتطوير أنظمة عالية الاستقرار والأداء.
توفير الموارد والذاكرة
على الرغم من أنّ الفروق صارت أقل حدة في بعض النواحي، إلا أنّ المشاريع الضخمة التي تتطلّب أقصى أداء ممكن أو تعمل في بيئات موارد محدودة (مثل الأنظمة المدمجة Embedded Systems) غالبًا ما تفضل استخدام لغات مترجمة لتلافي الأعباء الزمنية للتفسير. أما في حالات العمل التفاعلي أو عند بناء تطبيقات ويب مبنية على لغات سكربت، يميل المبرمجون إلى اللغات المفسّرة لسهولة النشر والتطوير.
إدارة الأخطاء والتصحيح
تقدّم المترجمات عادةً واجهة قوية في الكشف عن الأخطاء النحوية والدلالية أثناء عملية البناء. وبذلك فإن معظم الأخطاء تُحصر قبل أن يتم تشغيل البرنامج، مما يوفّر درجة إضافية من الأمان والاستقرار. في المقابل، يمكّن المفسّر المبرمجين من اكتشاف الأخطاء المنطقية والبرمجية بسرعة أثناء التشغيل التفاعلي، ما قد يوفّر مرونة كبيرة في تصحيح الأخطاء على الفور.
التوزيع والحماية
قد تكون إحدى الأمور التي تقلق بعض المؤسسات: حماية الشفرة المصدرية. فحين تُوزّع برامج مترجمة، يمكن للمستخدم النهائي تشغيل الملف التنفيذي دون رؤية الكود المصدري بشكل مباشر. أما في حالة اللغات المفسّرة، غالبًا ما يكون الكود مكشوفًا للمستخدم النهائي أو على الأقل في صورة شبه مكشوفة (كما في ملفات .pyc للبايثون). بالرغم من وجود تقنيات “التشويش” (Obfuscation) إلا أنّ النموذج المترجم يعدّ أكثر أمنًا من ناحية إخفاء تفاصيل الشفرة الأصلية.
مستقبل المترجمات والمفسّرات
شهدنا في السنوات الأخيرة تطورًا ملحوظًا في آليات بناء وتنفيذ البرامج، إذ إنّ المفهوم التقليدي للمترجم والمفسّر آخذ في التحوّل نحو نماذج أكثر تعقيدًا ورشاقة. فمثلاً، تعتمد الكثير من محركات جافا سكربت الحديثة على ترجمة جزئية (JIT) للشفرة عند التنفيذ بهدف تحسين الأداء. كما تدمج بعض تقنيات الذكاء الاصطناعي الآن أدوات تحليل ستاتيكي وديناميكي للشفرة لمعرفة مواضع الاختناقات البرمجية والتحسين عليها.
قد يؤدي ظهور تقنيات الحوسبة السحابية والحاويات الافتراضية (Containers) مثل Docker وKubernetes إلى إعادة تشكيل مفهوم الأداء والاعتمادية، نظرًا لإمكانية توزيع الأحمال وموازنة الأعباء عبر بنيات تحتية قوية. ومع ذلك تبقى الأسس المفاهيمية للمترجم والمفسّر كما هي: إما تحويل الشفرة مسبقًا إلى لغة الآلة قبل التنفيذ، أو تفسير الأوامر في الزمن الفعلي خطوة بخطوة.
أهمية فهم المفهومين للمبرمجين
مع أنّ كثيرًا من المبرمجين يستسهل اختيار لغة ما بناءً على شعبيتها أو ترند السوق، إلا أنّ فهم الآلية الداخلية للتنفيذ يكتسب أهمية قصوى عند الحاجة لاتخاذ قرار تقني حاسم. تتضح هذه الأهمية بصورة أكبر عندما يواجه المهندسون مشكلات متعلقة بالأداء أو الذاكرة، أو عندما يتطلّب المشروع بنى معقدة للتشغيل على منصات مختلفة.
وفي حال أردت تطوير نظام تفاعلي محمول على الويب بسرعة، فربما تفضّل لغة مفسّرة مثل بايثون أو روبي، لأنها تسمح بالتغييرات والتحديثات اللحظية. أمّا إذا كنت تنوي بناء محرك ألعاب أو برمجيات طبية حساسة تحتاج إلى الأداء الأمثل، فقد تتجه نحو لغات مترجمة مثل سي++ أو رست، وإلى تقنيات بناء قوية تتيح التحكم الدقيق في الذاكرة وآليات التجميع.
الأخطاء الشائعة في فهم الفروقات بين المترجم والمفسّر
- افتراض أن اللغات المترجمة دائمًا أسرع من المفسّرة: في العموم يُعدّ هذا الافتراض صحيحًا، لكن التطورات التقنية في نماذج الترجمة الجزئية والدوال الأصلية (Native Functions) في بعض اللغات المفسّرة جعلت هذا الفرق ليس مطلقًا.
- اعتبار أن اللغات المفسّرة أسهل دائمًا: مع أن التفسير يتيح مرونة في البدء والتركيز على المنطق دون الاهتمام بعملية الترجمة، إلا أنّ صعوبة اللغة تعود أيضًا إلى مدى تعقيد قواعدها ومكتباتها.
- اعتبار أن الملفات التنفيذية في اللغات المترجمة لا يمكن الرجوع منها للشفرة الأصلية: صحيح أن الرجوع الكامل للشفرة الأصلية أمر معقد، لكنه ليس مستحيلًا. توجد أدوات هندسة عكسية تستطيع استخراج بنية برمجية ما من ملف تنفيذي، وإن كان ذلك بدرجة محدودة.
- الخلط بين بيئة التطوير والمفاهيم الأساسية: أحيانًا يظن البعض أن استخدام بيئة تطوير متكاملة (IDE) يعمل كمفسّر في خلفيته، بينما في الحقيقة يمكن أن تكون البيئة IDE مجرد وسيط بواجهات رسومية ومحررات نصية لكنها تعتمد على مصنّعات Compilers أو مفسّرات Interpreters خارجية.
الاعتبارات العملية في المشاريع الواقعية
تظهر في المشاريع الواقعية اعتبارات عديدة تجعل عملية الاختيار بين المترجم والمفسّر أو الجمع بينهما معقدة، وأبرز هذه الاعتبارات:
- متطلبات الوقت الحقيقي: بعض التطبيقات (مثل برمجيات المعالجة الفورية للبيانات أو الأنظمة المدمجة) تحتاج لتنفيذ فائق السرعة، فتُعدّ اللغات المترجمة خيارًا أفضل.
- قابلية الصيانة والتوسّع: كثير من لغات التفسير توفر أنظمة نمطية (Modules) وخدمات شاملة لصيانة الشفرة وتمكين التعاون بين الفرق الكبيرة.
- التوافقية بين المنصات: في حال الحاجة إلى تشغيل البرنامج على منصات متعددة بدون إعادة بناء لكل منصة، فإن النهج الهجين (مثل جافا) أو لغات المفسّر قد تكون أيسر.
- سهولة التعلم والتوظيف: تتدخل عوامل مثل مستوى مجتمع الدعم والموارد التعليمية لتحديد اللغة المُعتمدة، بغض النظر عن كونها مترجمة أو مفسرة.
دور المترجم والمفسّر في مجال التعليم والأبحاث
تعد دراسة بناء المترجمات وتصميم المفسّرات من المواد الأساسية في تخصص علوم الحاسوب. ففي مساقات تصميم المترجمات (Compiler Design) يُدرّس الطلبة مفاهيم تحليل اللغات الرسمية، ونظريات أوتوماتية الحالات المنتهية (Finite Automata)، وتحليل السياق الحر (Context-Free Grammars)، وكيفية تنفيذ ذلك عمليًا عبر أدوات بناء المترجمات مثل Lex وYacc أو ما يناظرها مثل Flex وBison.
أما في مجال المفسّرات، فإن التركيز يتجه نحو عمليات التنفيذ التفاعلي وفهم نموذج تخزين المتغيرات في الذاكرة زمن التشغيل، وأسلوب إدارة الذاكرة التلقائي (Garbage Collection) في بعض اللغات، بالإضافة إلى تقنيات التصحيح اللحظي. ويسهم فهم هذه الآليات في تطوير أدوات جديدة تُساعد الباحثين على بناء لغات خاصة بالمجالات (Domain-Specific Languages)، مما يوسّع آفاق التطوير في مجالات علمية وهندسية متخصصة.
مدارس فكرية في تصميم لغات البرمجة
يختلف مصممو اللغات في فلسفتهم حول كيفية تقديم الأدوات للمبرمجين. ففي حين يركز فريق على الاستفادة القصوى من إمكانات العتاد بالاعتماد على مترجمات قوية تُنتج شفرة عالية الأداء (مثل لغة سي++)، فإن فريقًا آخر يولي الأولوية للتجريبية والسرعة في الحصول على المخرجات (مثل بايثون ولغات السكربت). وهناك من يمزج بين الطرفين في نسق مُبتكر (مثل جافا وسي شارب).
لا يمكننا القول بوجود مدرسة صحيحة وأخرى خاطئة؛ إنما يعتمد الأمر على الهدف من اللغة أو المشروع، فقد تكون السرعة الفائقة أهم المتطلبات في تطبيقات الألعاب عالية الدقة أو برمجيات التحكم الآني، بينما قد تهيمن الاعتبارات الإنتاجية وسرعة التطوير في النظم المكتبية وتطبيقات الويب. ومن هنا تنشأ الحاجة إلى مراعاة هذه المدارس عند اختيار اللغة المناسبة.
تأثير التوجهات الحديثة كالحوسبة السحابية و”السيرفرليس”
شهدنا في العقد الأخير تصاعدًا في الاعتماد على الحوسبة السحابية ونماذج “السيرفرليس” (Serverless Computing)، حيث تُنفذ الدوال أو الخدمات في بيئات تُدار بالكامل من مزودي الخدمات السحابية (مثل AWS Lambda وGoogle Cloud Functions). في هذه الحالات، تكتسب سرعة الانطلاق (Cold Start) أهمية بالغة، وهي الفترة الزمنية التي يستغرقها النظام قبل بدء معالجة الطلب الأول.
تؤثر هذه النقطة على قرار استخدام لغة مترجمة أو مفسّرة. فقد يؤدي استخدام لغة مفسّرة إلى بطء ملحوظ في وقت “الانطلاق البارد”، لأن البيئة تحتاج لتهيئة المفسّر وتشغيل الشفرة. بالمقابل، قد تتطلب بعض اللغات المترجمة حجمًا كبيرًا من الملفات التنفيذية مما يُزيد من زمن التحميل. لهذا نجد بعض المنصات تميل إلى نماذج هجينة أو إلى لغات بعينها تحقق توازنًا بين حجم الملف التنفيذي وزمن التشغيل الأولي.
اعتبارات أمنية
يلعب اختيار التقنية البرمجية أيضًا دورًا في تصميم الجوانب الأمنية للتطبيق. إذ تُسهّل بعض النماذج المفسّرة إدراج الشفرة الضارة إذا كان بإمكان المهاجم حقن أوامر جديدة في أثناء التشغيل. في حين قد يكون المترجم أكثر صرامة لأنه ينشئ ملفًا ثنائيًا ثابتًا يقلل من إمكانية التعديل المباشر. ومع ذلك، فإن الأمان في النهاية يعتمد على مستويات أخرى من حماية النظام وسد الثغرات المحتملة في بيئة التنفيذ.
الترجمة الجزئية (Just-In-Time) ودورها في تسريع اللغات المفسّرة
من أهم الاختراقات الحديثة في عالم التفسير تلك المتعلقة بخوارزميات الترجمة الجزئية JIT. تعتمد هذه التقنية على ملاحظات التشغيل في الزمن الفعلي لتحديد المقاطع الأكثر استخدامًا (Hot Spots)، ثم تُترجم تلك المقاطع بشكل انتقائي إلى شفرة آلة سريعة التنفيذ. تُستخدم هذه التقنية في محركات جافا سكربت الحديثة (مثل V8) وفي آلة جافا الافتراضية (JVM). والنتيجة هي الوصول أحيانًا لأداء يقارب أداء اللغات المترجمة التقليدية في بعض جوانب التطبيقات.
تكمن الفكرة في التوازن بين “التفسير البحت” الذي يكون مرنًا ولكن بطيئًا، و”الترجمة الكاملة المسبقة” (AOT: Ahead-Of-Time) التي قد تُطيل زمن البناء الأوّلي. فتحاول JIT أن تجمع بين حسنات الطريقتين، إذ يبدأ البرنامج تنفيذه عبر التفسير، ثم كلما تكررت مقاطع معينة تُعرَّف على أنها “ساخنة” فتُترجم وتُحسّن؛ مما يعطي زيادة واضحة في الأداء دون الانتظار طويلاً قبل بداية التشغيل.
ملخص
المترجم Compiler والمفسر Interpreter في واقع الأمر عبارة عن برنامجين يقومان بنفس الغرض، والمتمثل في تحويل الأوامر المكتوبة بإحدى لغات البرمجة العالية المستوى (high level language) من قبيل Java و#C و++C، إلى لغة الآلة Machine Language (أوامر مكتوبة بالبيانات الثنائية Binary Data أي سلاسل من الأصفار والوحدات).
إذاً وإن كان لهما نفس الدور، فلماذا يوجد مترجم “Compiler” ومفسر “Interpreter” ولماذا لا يوجد أحدهما فقط ؟
لنتعرف على أهم الفروق بين البرنامجين، وعلى السبيل الذي يسلكه كلاهما من أجل تحويل التعليمات والأوامر العالية المستوى (والتي تسمى أيضاً البرنامج المصدري Source Program) إلى أوامر مكتوبة بلغة الآلة.
المترجم Compiler :
من خلال اسمه يتضح جلياً أنه يقوم بعملية الترجمة، فهو يقوم بفحص البرنامج المكتوب بلغة البرمجة كاملاً، ثم يقوم بترجمته إلى برنامج مكتوب بلغة الآلة لكي تتمكن وحدة معالجة البيانات “CPU” من تنفيذه و لا يظهر الأخطاء الموجودة في البرنامج المصدري إلاّ بعد الانتهاء من عملية تحويله إلى لغة الآلة.
المفسر Interpreter :
يقوم تقريباً بنفس الدور الذي يقوم به المترجم مع اختلاف بسيط، يتجلى في أن المفسر لا يقوم بتحويل الكود المصدري إلى كود الآلة مباشرة وإنما يقوم بتحويله إلى لغة وسيطة (intermediate code)، بعد ذلك يتم تحويل كل جزء من أجزاء الكود الناتج إلى لغة الآلة، ثم يتم تنفيذ هذه الأجزاء أمراً بأمر (Statement by statement)، وأي أمر يضم خطأً يؤدي إلى توقيف عملية تحويل الأجزاء المتبقية.
خلاصة شاملة
لا شك أنّ الفروق بين المترجم والمفسّر تعد من الجوانب الأساسية في علوم الحاسوب، وتنعكس نتائج الاختيار على دورة حياة النظام بأكملها، بدءًا من مرحلة التصميم والكتابة، وصولًا إلى مرحلة نشر التطبيق وصيانته وتطويعه للمستقبل. ويظل فهم البنية الداخلية لكليهما أمرًا بالغ الأهمية لأي مبرمج يطمح للتعمّق في مفاهيم بناء اللغات وتصميم الأنظمة البرمجية.
ورغم أنّ الاعتماد على المترجم قد يبدو الأنسب للمشاريع عالية التعقيد والأداء، فإن المفسّر يتيح مرونة وحيوية أكبر في بعض أنواع المشاريع، وخاصة تلك القائمة على التفاعل السريع والاختبارات المتكررة. ولعلّ التطوّرات التقنية مثل JIT قد جسّرت الهوّة بين هذين النموذجين، وجعلت الخطوط الفاصلة أقل حدّة مما كانت عليه سابقًا.
المراجع والمصادر
- Aho, A. V., Lam, M. S., Sethi, R., & Ullman, J. D. (2006). Compilers: Principles, Techniques, & Tools (2nd Edition). Addison-Wesley.
- Appel, A. W. (2004). Modern Compiler Implementation in C. Cambridge University Press.
- Muchnick, S. S. (1997). Advanced Compiler Design and Implementation. Morgan Kaufmann.
- Nanz, S., & Furia, C. A. (2015). A comparative study of programming languages in Rosetta Code. Proceedings of the 37th International Conference on Software Engineering, IEEE Press.
- Briggs, P. (1992). Register Allocation via Graph Coloring. Rice University.
- Documentation on Python, Ruby, Java, and JavaScript engines provided by official language websites:
بذلك يكون هذا العرض قد أحاط بالفروقات بين المترجم والمفسّر من جوانب عدة: المفاهيم الأساسية، المراحل التشغيلية، أوجه المقارنة في الأداء واستغلال الموارد، فضلاً عن الرؤية المستقبلية للغات البرمجة المختلطة والتقنيات الحديثة. يُفترض بالقارئ الآن امتلاك نظرة عميقة حول الأسس التي يستند إليها بناء المترجمات والمفسّرات، وعلاقة ذلك باختيار اللغة الأفضل للمهمة المطلوبة.
تظل هذه الموضوعات في قلب علوم الحاسوب والبرمجيات، إذ تتقدم التقنيات ويتزايد تعقيد الأنظمة، ما يدفع الباحثين والمطورين نحو ابتكار مقاربات جديدة أو دمج القديم بالجديد في إطار تطبيقي شديد التنوع.