تُعد قواعد البيانات NoSQL (اختصاراً لعبارة “Not Only SQL”) من التوجهات الحديثة في عالم تخزين البيانات ومعالجتها. ظهرت للواجهة مع تسارع حاجات المؤسسات إلى الأنظمة التي تستطيع التعامل مع كميات هائلة من البيانات المتولّدة باستمرار وبسرعة فائقة. في الأنظمة التقليدية المعتمدة على قواعد بيانات علائقية (Relational Databases)، يمكن أن تصطدم الشركات بقيود الأداء وقابلية التوسع عند الوصول إلى نطاقات ضخمة من البيانات والمعاملات. جاءت NoSQL لتقدم حلولاً أكثر مرونة وتوسعية، مع إمكانات عالية في التعامل مع البيانات شبه الهيكلية أو غير الهيكلية (Unstructured and Semi-structured Data). في هذا المقال المطول جداً سيتناول النقاش جذور نشأة NoSQL، وأنواعها المختلفة، وكيف تتميز عن قواعد البيانات العلائقية، وسنخوض في العمق حول مزاياها وعيوبها، وطرق استخدامها، وأشهر الأمثلة عليها. كما سيشتمل المقال على تفصيل مستفيض للمفاهيم النظرية والعملية التي تقوم عليها، مدعومة بأمثلة واقعية من تطبيقات عالمية. وفي الختام، ستُقدَّم بعض المراجع والمصادر المهمة لكل من يرغب في التوسع أكثر في هذا المجال.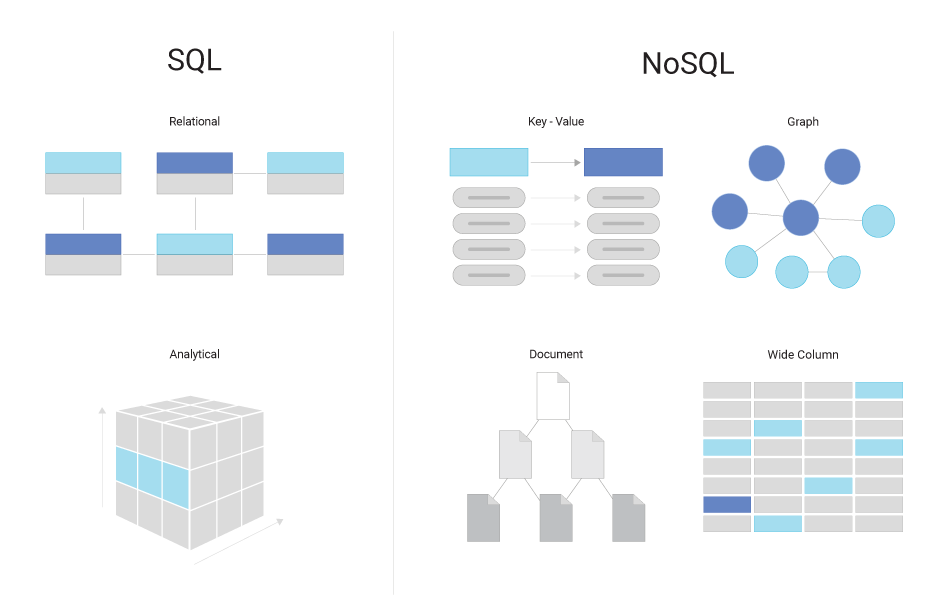
التطوّر التاريخي لقواعد البيانات: من العلائقية إلى NoSQL
مرحلة ما قبل قواعد البيانات العلائقية
قبل ظهور قواعد البيانات العلائقية، كانت أنظمة إدارة البيانات مبنية على نماذج هرمية أو شبكية. كانت تلك النماذج تستلزم تعريفات ثابتة للعلاقات بين البيانات، مما يزيد من التعقيد عند محاولة تغيير بنية البيانات أو توسيعها. حينها، لم يكن هناك مفهوم “SQL” بالمعنى المعروف حالياً، بل كانت هناك لغات وإجراءات مختلفة مخصصة لكل نظام على حدة. وكان مفهوم التكامل والاتساق (Consistency) ما يزال محدوداً، إذ كانت البيانات مخزنة غالباً في ملفات متفرقة.


واجهت تلك النظم القديمة تحديات في المرونة والأداء عندما تصبح البيانات كبيرة أو تتطلب عمليات معقدة. كما لم تكن قابلة للتوسع الأفقي بشكل فعّال؛ فغالباً ما يقتصر التوسع على إضافة عتاد جديد للخادم نفسه (Scale-Up) بدلاً من توزيع الحمل على أكثر من خادم (Scale-Out). هذه المعضلات دفعت المبرمجين والباحثين إلى محاولة إيجاد حلول جديدة أكثر ديناميكية.
ظهور قواعد البيانات العلائقية
في السبعينيات من القرن الماضي، اقترح عالم الرياضيات إدغار كود (Edgar F. Codd) النموذج العلائقي (Relational Model) الذي أحدث نقلة نوعية في كيفية تخزين البيانات والوصول إليها. سهّل هذا النموذج عمليات الإضافة والاستعلام وتعديل البيانات عن طريق لغة بنيوية موحدة تُسمى SQL (Structured Query Language). وقد قدّم النموذج العلائقي مفاهيم الجداول (Tables) والأعمدة (Columns) والصفوف (Rows) والمفاتيح (Keys)، مما جعل تصميم قواعد البيانات أسهل من ذي قبل وأكثر منهجية. كما ظهرت مُتحكمات المعاملات (Transaction Controllers) لضمان اتساق البيانات، بما عُرف بخصائص ACID (Atomicity, Consistency, Isolation, Durability). ولفترة طويلة، هيمنت قواعد البيانات العلائقية على المشهد في أغلب التطبيقات الحاسوبية، سواء في قطاع المال والأعمال، أو التجارة الإلكترونية، أو القطاعات الحكومية.
لكن مع انتشار الإنترنت وتزايد حجم البيانات بشكل انفجاري بدءاً من العقد الأخير من القرن العشرين، بدأت تظهر احتياجات جديدة لم تكن متوافرة في أنظمة قواعد البيانات العلائقية. فهذه الأخيرة قد تواجه قيوداً في ما يتعلق بالأداء عند التعامل مع مليارات السجلات في الوقت الفعلي، بالإضافة إلى تعقيدات في توزيع البيانات على خوادم متعددة (Distributed Databases). من هنا برزت التساؤلات حول مدى قدرة النماذج العلائقية على تلبية احتياجات التطبيقات السحابية والويب الضخمة.
بزوغ فجر NoSQL
أواخر العقد الأول من القرن الحادي والعشرين، بدأت شركات تقنية عملاقة مثل جوجل، أمازون، وفيسبوك بتطوير حلول داخلية للتعامل مع الأحجام الهائلة من البيانات المتدفقة والموزعة جغرافياً في مراكز بيانات مختلفة. وكانت لدى هذه الشركات تحديات خاصة تتطلب خصائص محددة، مثل قابلية التوسع الأفقي، ومعالجة البيانات غير المهيكلة أو شبه المهيكلة (مثل بيانات الشبكات الاجتماعية، والسجلات النصية الضخمة، وملفات الوسائط المتعددة). ولّد ذلك ما بات يُعرف بمفهوم NoSQL، أو بشكل أدق “Not Only SQL”، كإشارة إلى أن هذه النظم لا تهدف لإلغاء قواعد البيانات العلائقية أو لغتها SQL، بل لتقديم بديل أو مكمل عندما لا تكون القواعد العلائقية هي الخيار الأمثل.
انطلقت موجة الاهتمام بـNoSQL مع نشر أوراق بحثية مثل Bigtable من جوجل، و Dynamo من أمازون، و Cassandra التي طورتها فيسبوك بالأساس وتبرعت بها لمجتمع المصادر المفتوحة. أثبتت هذه النظم نجاحها في تقديم أداء عالٍ وقابلية توسّع كبيرة عبر مئات وآلاف الخوادم. ومع بروز هذه النجاحات، بدأ المطوّرون والمهندسون في مختلف الشركات – وليس فقط الشركات العملاقة – ينظرون إلى NoSQL كحل رئيسي للعديد من التحديات الجديدة في عصر البيانات الضخمة (Big Data). وشيئاً فشيئاً، صار الاهتمام بـNoSQL يعم مختلف قطاعات التكنولوجيا وصولاً إلى مجالات أخرى مثل إنترنت الأشياء (IoT) وتحليلات البيانات الضخمة.
أنماط وتصنيفات قواعد بيانات NoSQL
على عكس قواعد البيانات العلائقية التي تتشارك غالباً في نموذج موحد مبني على الجداول، نجد في عالم NoSQL عدة أنماط مختلفة، ولكل نمط فلسفته وبنيته الخاصة. الاختلاف في البنية يؤدي بالضرورة إلى اختلاف في كيفية تخزين البيانات والاستعلام عنها وكيفية ضمان تناسقها. تُعدّ هذه المرونة الكبيرة نقطة جاذبة تجعل NoSQL خياراً جذاباً للتطبيقات ذات المتطلبات المتخصصة.
قواعد البيانات القائمة على المفاتيح والقيم (Key-Value Stores)
تُعتبر هذه الفئة أبسط أشكال NoSQL؛ إذ تُخزّن البيانات على شكل أزواج مفتاح-قيمة (Key-Value). يُفهرس كل سجل بمفتاح فريد، بينما القيمة قد تكون أي نوع من البيانات سواء نصاً، كائناً ثنائيّاً، أو ملف JSON وغيرها. غالباً ما يكون الوصول سريعاً جداً للبيانات عبر المفتاح، مما يجعل هذا النمط مناسباً للتطبيقات التي تحتاج إلى سرعات عالية في القراءة والكتابة.
يتم التخزين عادةً في الذاكرة الرئيسية أو في ملفات نظامية مبسطة أو تقنيات تخزين أخرى تسمح بالتوسع الأفقي عبر توزيع أزواج المفاتيح والقيم على عقد (Nodes) متعددة. لكن بالمقابل، لا توفر هذه النظم غالباً إمكانات متقدمة للاستعلام المعقد. أشهر الأمثلة على هذه الفئة Redis و Riak و Amazon DynamoDB.
قواعد البيانات الوثائقية (Document Stores)
في هذا النمط، تُمثَّل البيانات بهيئة وثائق (Documents) بدلاً من صفوف وأعمدة، وغالباً ما تكون هذه الوثائق بصيغة JSON أو BSON أو XML. يمكن للوثيقة أن تحتوي على حقول فرعية، ومصفوفات، وهياكل معقدة متنوعة. توفر الأنظمة الوثائقية واجهات برمجية تسمح بالاستعلام حسب خصائص الوثيقة الداخلية وليس فقط عن طريق مفتاح أساسي واحد.
تتميز قواعد البيانات الوثائقية بمرونة عالية في بنية البيانات، إذ يمكن إضافة حقول جديدة بسهولة دون الحاجة لتغيير بنية قاعدة البيانات ككل. هذا النمط يناسب تماماً التطبيقات التي تتطلب تغييرات بنيوية متكررة أو التي لا تتبع نمطاً موحداً لكل البيانات. من أشهر الأمثلة MongoDB و CouchDB.
قواعد البيانات ذات الأعمدة العريضة (Wide-Column Stores)
تختلف هذه الفئة عن النمط الوثائقي في أنها تركز على تخزين البيانات في جداول تحتوي على أعمدة، لكن بشكل مرن يسمح بإضافة أعمدة جديدة دون هيكلة صارمة على مستوى الجدول. يعتمد العديد من هذه النظم على معمارية مستوحاة من ورقة Bigtable من جوجل. في هذا النمط، يمكن لمستخدم أو تطبيق ما إنشاء آلاف أو ملايين الأعمدة لعناصر مختلفة ضمن نفس الجدول دون تأثير كبير على بنية الجدول.
تُعتبر قواعد البيانات ذات الأعمدة العريضة ملائمة للسيناريوهات التي تتطلب تخزين أحجام هائلة من البيانات الموزعة على نطاق واسع، مع قابلية عالية للتوسع الأفقي. أمثلة شائعة على هذا النمط تشمل Apache Cassandra و HBase.
قواعد البيانات البيانية (Graph Databases)
تُخزّن البيانات على شكل عقد (Nodes) وعلاقات (Edges) وخصائص (Properties). يُعد هذا النمط مناسباً للتطبيقات التي تتطلب تمثيلاً غنياً للكيانات وعلاقتها المعقدة، مثل شبكات التواصل الاجتماعي، وأنظمة التوصية (Recommendation Systems)، وتحليل الروابط بين العناصر. تُمكِّن قواعد البيانات البيانية من تنفيذ استعلامات متقدمة على العلاقات بسرعة فائقة مقارنة بتخزينها في بنى علائقية أو وثائقية.
عندما يكون نموذج البيانات متمركزاً حول العلاقات بين الكيانات، تُعد قواعد البيانات البيانية خياراً ممتازاً نظراً لقدرتها على إجراء العمليات الملاحية (Traversals) بكفاءة. من أشهر هذه القواعد Neo4j و ArangoDB و OrientDB.
مفاهيم أساسية في عالم NoSQL
مفهوم BASE مقابل ACID
في قواعد البيانات العلائقية، يسعى المطوّرون إلى تحقيق خصائص ACID للحفاظ على اتساق البيانات في ظل معاملات (Transactions) متعددة. تشير هذه الخصائص إلى:
- Atomocity: ضمان تنفيذ المعاملة بأكملها أو إلغائها بالكامل.
- Consistency: الحفاظ على قواعد السلامة والقيود المفروضة على البيانات.
- Isolation: منع تأثّر المعاملات ببعضها قبل اكتمال أي منها.
- Durability: ضمان بقاء التغييرات حتى بعد انقطاع الطاقة أو حدوث خلل ما.
لكن في العديد من نظم NoSQL (وخصوصاً الموزعة)، تتحول الأولوية إلى خصائص BASE التي تُعد اختصاراً لـ:
- Basically Available: توفر النظام بدرجة عالية، حتى لو كان ذلك على حساب بعض الميزات.
- Soft-state: حالة النظام يمكن أن تتغير مع الوقت في ظل عمليات المزامنة.
- Eventual Consistency: الاتساق النهائي، بمعنى أن جميع العقد تحصل على نسخة من البيانات في نهاية المطاف، لكن ليس بالضرورة لحظياً.
يُعد التركيز على توافر الخدمة (Availability) وقابلية التوسع (Scalability) من سمات العديد من حلول NoSQL، مع قبول بعض التنازلات المؤقتة في اتساق البيانات الفوري (Immediate Consistency). هذه المرونة في الاتساق يمكن أن تكون ميزة إذا كان التطبيق يستطيع تحمل تأخير زمني قبل اتساق البيانات بين جميع العقد.
نظرية CAP في الأنظمة الموزعة
تُعد نظرية CAP (اختصاراً لـ Consistency, Availability, Partition Tolerance) من المبادئ الأساسية لفهم القرارات المعمارية في الأنظمة الموزعة وبالأخص NoSQL. تنص هذه النظرية على أنه لا يمكن لنظام موزع تحقيق الميزات الثلاثة معاً في آن واحد، وعليه أن يختار تحقيق ميزتين على حساب الثالثة:
- Consistency (C): أن تظل جميع العقد تمتلك نفس البيانات في نفس الوقت.
- Availability (A): أن يظل النظام متاحاً للعمل حتى في حال فشل بعض العقد.
- Partition Tolerance (P): أن يواصل النظام العمل حتى عند انقطاع الاتصال بين بعض العقد.
توفر قواعد البيانات العلائقية تقليدياً ميزة الاتساق (C) وقابلية التحمل أمام الانقسامات (P) بشكل محدود إلى حد ما، ولكنها قد تفقد التوافر العالي عند توزيع البيانات على مسافات جغرافية شاسعة. أما معظم حلول NoSQL فهي تفضل غالباً التوافر (A) والتحمل أمام الانقسام (P)، مع قبول تنازلات في الاتساق (C). لكن هذا لا يعني أن جميع نظم NoSQL تقدم نفس المزيج، بل تختلف تصميماتها تبعاً لأولويات التطبيق والمخاطر التي يمكن تحمُّلها.
التجزئة (Sharding) وإعادة توزيع البيانات
العديد من نظم NoSQL مُصمَّمة للتشغيل على شبكات موزعة. واحدة من التقنيات الرئيسة لتحقيق ذلك هي التجزئة (Sharding). تقوم الفكرة على تقسيم مجموعة البيانات الضخمة إلى أجزاء (Shards)، وتخزين كل جزء في عقدة (أو مجموعة من العقد). بالتالي، يتم توزيع الحمل على كافة العقد بدلاً من تركيزه في مكان واحد.
تخضع طريقة تجزئة البيانات لاستراتيجيات مختلفة، فقد يكون التقسيم حسب مفتاح معين (Range-based Sharding)، أو حسب تجزئة دائرية (Hash-based Sharding)، أو عبر أساليب أخرى. يستلزم ذلك وجود منطق يحدد مكان تواجد البيانات المطلوبة عند تنفيذ أي عملية قراءة أو كتابة.
تعد قابلية التوسع الأفقي (Horizontal Scalability) من أبرز الفوائد التي تحققها هذه الاستراتيجية، حيث يصبح بالإمكان إضافة عقد جديدة لتوسيع السعة التخزينية أو تعزيز الأداء. ومع ذلك، يتطلب تطبيق Sharding إدارة دقيقة للتأكد من اتساق البيانات عبر العقد المختلفة، وضمان عدم تولّد اختناقات في الشبكة عند انتقال البيانات أو إعادة توزيعها.
النسخ والتكرار (Replication)
توفر أنظمة NoSQL عادةً إمكانات نسخ البيانات (Replication) على عدة عقد لزيادة الاعتمادية والموثوقية. الغرض من النسخ هو:
- ضمان التوافرية: إذا تعطّلت عقدة معينة، تظل العقد الأخرى قادرة على خدمة الطلبات.
- تقليل زمن الاستجابة: بوضع النسخ في مواقع جغرافية أقرب للمستخدمين.
- تحسين القدرة على التحمل أمام الكوارث: مثلاً في حالة حدوث عطب في مركز بيانات بأكمله.
يمكن تنفيذ النسخ بأساليب مختلفة، مثل النسخ المتزامن (Synchronous Replication) أو غير المتزامن (Asynchronous Replication). في النسخ المتزامن، يُضمن أن كل عملية كتابة تتم في جميع النسخ قبل اعتبار العملية ناجحة، وهذا يحقق اتساقاً أعلى ولكنه يبطئ الأداء. في النسخ غير المتزامن، تُعدّ العملية ناجحة بمجرد كتابة البيانات في نسخة واحدة على الأقل، بينما تصل البيانات للنسخ الأخرى لاحقاً، مما يزيد السرعة لكنه قد يخفّض درجة الاتساق.
التوافر العالي (High Availability)
دأبت أنظمة NoSQL على توفير آليات للتحمل أمام الأعطال بشكل أوتوماتيكي. في كثير من الأحيان، تعتمد الأنظمة على معمارية خالية من أي نقطة فشل واحدة (Single Point of Failure). يتم تكرار البيانات على عدة عقد، بحيث لو تعرّضت عقدة لعطل، تُستبدل تلقائياً بعقدة أخرى تملك نسخة محدثة أو شبه محدثة من البيانات.
مع ذلك، تتطلب هذه الآليات تخطيطاً دقيقاً من قبل مديري النظم، بما في ذلك توزيع العقد جغرافياً، وإجراء اختبارات وتحميل مستمر للتأكد من جاهزية الأنظمة للتعامل مع الأحداث الطارئة. يضاف لذلك استراتيجيات إعادة التوجيه (Failover) التي يحددها النظام الموزع، بحيث لا يشعر المستخدم بأي انقطاع ملحوظ عند حدوث فشل في عقدة أو أكثر.
تحديث المخطط (Schema Evolution)
واحدة من الأمور التي تميّز أغلب قواعد بيانات NoSQL هي عدم اعتمادها على مخطط صارم (Schema-Less أو Schema-Flexible). في قواعد البيانات العلائقية، يجب تحديد أعمدة الجداول وأنواع البيانات بشكل دقيق مسبقاً، وأي تغيير لاحق في البنية يتطلب إجراءات معقدة واحتمالية توقف مؤقت للنظام.
أما في كثير من نظم NoSQL، يمكن إضافة حقول جديدة أو حذف حقول قديمة دون الحاجة إلى عملية تحويل شاملة (Migration) على مستوى قاعدة البيانات. هذا يمكّن المطورين من الابتكار بسرعة، وتلبية التغيرات المستمرة في متطلبات التطبيق دون الحاجة لتعطيل النظام أو إعادة تصميم الجداول.
مقارنة بين قواعد البيانات العلائقية وNoSQL
نموذج البيانات والتصميم
تعتمد القواعد العلائقية على مفهوم الجداول ذات الأعمدة المحددة مسبقاً والعلاقات الصريحة (Foreign Keys). بينما تعتمد NoSQL في الأساس على نماذج أكثر تنوعاً: مفاتيح وقيم، وثائق، أعمدة عريضة، أو بيانية. وهذا ينعكس على طريقة تصميم التطبيقات، حيث تتبع قواعد البيانات العلائقية منهج التطبيع (Normalization) لتجنّب التكرار، بينما تميل NoSQL إلى إلغاء التطبيع (Denormalization) بهدف رفع الأداء وتقليل الحاجة للربط في وقت الاستعلام.
قابلية التوسع والحمولات الكبيرة
تتميز NoSQL عادةً بقدرتها العالية على التوسع الأفقي عبر إضافة عقد جديدة في أي وقت. أما القواعد العلائقية التقليدية فغالباً ما يتم توسيعها عمودياً بإضافة موارد أقوى على خادم واحد. بالطبع هناك أنظمة علائقية موزعة، ولكنها تتسم بقدر أكبر من التعقيد مقارنة ببعض أنظمة NoSQL التي صممت من الأساس لتكون موزعة.
اتساق البيانات
تلتزم قواعد البيانات العلائقية التزاماً صارماً بخصائص ACID، مما يضمن اتساقاً فورياً. بينما تفضّل NoSQL في العديد من الأحيان التوافرية العالية وقابلية التوزيع على حساب الاتساق الفوري، وهو ما قد يعني اتساقاً نهائياً (Eventual Consistency) في بعض الأوقات.
حالات الاستخدام الملائمة
- القواعد العلائقية: نظم المعاملات المالية، أنظمة تخطيط الموارد المؤسسية، وغيرها من التطبيقات التي تتطلب دقة واتساقاً عالياً.
- NoSQL: تطبيقات الويب سريعة النمو، تحليلات البيانات الضخمة، شبكات التواصل الاجتماعي، الأرشيف الضخم من المحتوى، أنظمة التوصية، وأنظمة إنترنت الأشياء.
المرونة في بنية البيانات
تميل NoSQL إلى السهولة في التعامل مع بيانات ذات بنيات متغيرة بسرعة أو غير معروفة مسبقاً، كبيانات الوسائط المتعددة أو سجلات الأحداث (Log Files). في المقابل، عندما يكون المخطط ثابتاً ويحتاج التطبيق إلى استعلامات مركبة ومعقدة باستخدام SQL، فقد تظل القواعد العلائقية الخيار الأكثر ملاءمة.
أنواع قواعد بيانات NoSQL بالتفصيل
بعد التطرق المختصر لتصنيفات قواعد البيانات NoSQL، من المفيد الغوص بشكل أعمق في كل فئة على حدة، مع سرد التطبيقات الشائعة لها وحالات الاستخدام المثلى.
1) قواعد البيانات القائمة على المفاتيح والقيم (Key-Value Stores)
المفهوم التفصيلي
يُخزّن كل عنصر في قاعدة بيانات من هذا النوع على شكل زوج مفتاح وقيمة. يشبه ذلك كثيراً هيكلة القاموس أو الخريطة في لغات البرمجة. المفتاح عادة ما يكون سلسلة نصية (String) أو قيمة رقمية تُستخدم لتعريف العنصر بشكل فريد. أما القيمة فقد تكون أي شكل من البيانات الخام أو المنظّمة. يندر أن يوجد مخطط (Schema) أو بنية داخلية معيّنة تُفرض على القيمة نفسها؛ فكل ما تهتم به القاعدة هو أن هذا المفتاح يُشير إلى تلك القيمة.
مزايا وعيوب
- مزايا:
- بنية بسيطة وسهلة الفهم.
- سرعة فائقة في عمليات القراءة والكتابة بناء على المفتاح.
- قابلية عالية للتوسع الأفقي بفضل التوزيع القائم على التجزئة.
- سهولة النسخ والتحميل الموزع.
- عيوب:
- صعوبة إجراء استعلامات معقدة على القيم؛ إذ لا وجود لفهارس داخلية.
- اضطرار المطوّر إلى تحمل مسؤولية إدارة بنيات البيانات في جانب التطبيق.
أمثلة عملية
Redis هو الأشهر في هذه الفئة، وغالباً ما يُستخدم كذاكرة تخزين مؤقت (Cache) أو كوسيط للرسائل (Message Broker)، إضافةً لاستخداماته في إدارة جلسات المستخدم. أما Amazon DynamoDB فيوفر خدمة مدارة بالكامل في السحابة، مما يتيح للمطورين بناء تطبيقات سريعة وقابلة للتوسع دون الانشغال بالبنية التحتية. كما يُعد Riak خياراً مفتوح المصدر يركز على الاتساق النهائي والتوزيع الجغرافي.
2) قواعد البيانات الوثائقية (Document Stores)
المفهوم التفصيلي
في قواعد البيانات الوثائقية، يتم تخزين كل سجل على هيئة وثيقة، وغالباً ما تكون هذه الوثيقة بصيغة JSON أو BSON (امتداد ثنائي لـ JSON) أو XML. يمكن للوثيقة أن تحتوي على بنية معقدة من الحقول والمصفوفات والتوابع الفرعية. تسمح معظم المنصات الوثائقية بإنشاء فهارس على الحقول الداخلية للوثائق، مما يسهل عمليات الاستعلام المركبة.
مزايا وعيوب
- مزايا:
- مرونة عالية في تغيير بنية الوثائق دون الحاجة لتحديث المخطط.
- دعم جيد للاستعلامات ذات الشروط المتعددة والفرز والترتيب.
- سهولة بناء نماذج الواجهة الخلفية في التطبيقات التي تعتمد على JSON.
- عيوب:
- قد لا تكون مثالية للعمليات المعقدة ذات العلاقات المتشابكة.
- استخدام الفهارس قد يؤثر على الأداء إن لم يُصمم بحكمة.
أمثلة عملية
MongoDB هو الأشهر في عالم الوثائق، ويقدم إمكانات واسعة للتخزين والاستعلام، إلى جانب واجهة غنية لإدارة النسخ والتجزئة. أما CouchDB فيتميز بتصميمه المعتمد على بروتوكول HTTP وملاءمته للبيئات غير المتصلة دائماً بالإنترنت (مثل أجهزة الموبايل) من خلال أسلوب المزامنة المتعدد.
3) قواعد البيانات ذات الأعمدة العريضة (Wide-Column Stores)
المفهوم التفصيلي
هذه الفئة مُلهَمَة بالورقة البحثية الشهيرة “Bigtable” من جوجل. يتم تخزين البيانات في جداول، ولكن كل صف يمكن أن يحتوي عدداً كبيراً جداً من الأعمدة التي تُقسم منطقياً إلى عائلات أعمدة (Column Families). في مثل هذه النظم، يمكن أن يحتوي صف واحد على أعمدة تختلف تماماً عن صف آخر. يعزز هذا النمط قدرة الأنظمة على تحمل النمو الهائل في حجم البيانات، مع توزيعها بسهولة على مئات أو آلاف العقد.
مزايا وعيوب
- مزايا:
- قابلية توسع أفقي هائلة.
- أداء عالٍ مع استعلامات القراءة والكتابة المتتالية.
- مناسب للتطبيقات التي تتطلب تحليل بيانات كثيفة أو تخزين سجلات ضخم.
- عيوب:
- تعقيد في بناء الاستعلامات إذا كانت غير مرتكزة على المفاتيح الأساسية.
- ضعف الدعم للعلاقات المباشرة مقارنة بالنمط العلائقي.
أمثلة عملية
Apache Cassandra من أشهر الأمثلة على هذا النمط، حيث يملك معمارية لامركزية (Decentralized Architecture) تتيح التوسع الكبير والاتساق النهائي. أما HBase فيبنى على قمة نظام ملفات Hadoop ويوفر تكاملاً قوياً مع منظومة Hadoop لتحليل البيانات الضخمة.
4) قواعد البيانات البيانية (Graph Databases)
المفهوم التفصيلي
في هذه الفئة، يتم تمثيل البيانات على شكل عُقَد (Nodes) تمثل الكيانات أو الكائنات، وعلاقات (Edges) تصف الارتباطات بين هذه العُقَد، وخصائص (Properties) تخزن المعلومات المتعلقة بكل من العقد والعلاقات. إذا كان التطبيق بحاجة إلى استعلامات مثل “ما هو أقصر طريق بين عقدة X وعقدة Y؟” أو “اكتشف جميع العقد المرتبطة بعقدة ما بمسافة محددة”، فإن قواعد البيانات البيانية توفر أداءً ممتازاً مقارنةً بهياكل الجداول أو الوثائق.
مزايا وعيوب
- مزايا:
- أداء عالٍ في استعلامات الرسم البياني، مثل شجرة الأصدقاء أو توصيات المنتجات.
- سهولة التعبير عن العلاقات المعقدة.
- تعامل مباشر مع نماذج بيانات الشبكات الاجتماعية وأنظمة التوصية.
- عيوب:
- قد تكون أقل كفاءة في تخزين بيانات غير مترابطة بشكل كبير.
- تحتاج إلى منحنيات تعلم لكيفية الاستعلام ومعالجة البيانات البيانية.
أمثلة عملية
Neo4j هو النظام الأكثر شهرة، حيث يوفر لغة استعلام تُسمى Cypher مصممة خصيصاً لمعالجة الرسوم البيانية. أما ArangoDB فيجمع بين مفهوم الوثائق والرسوم البيانية في نظام واحد متعدد النماذج، مما يتيح مرونة إضافية في كيفية تمثيل البيانات.
حالات استخدام NoSQL
الشبكات الاجتماعية والتواصل
تعتمد معظم الشبكات الاجتماعية الكبرى على NoSQL لتخزين بيانات المستخدمين وتحديثات الحالة والعلاقات بينهم. يتطلب ذلك القدرة على إدارة مليارات السجلات التي تتحدث باستمرار في الوقت الفعلي، مما يجعل الحلول التي توفر التوسع السريع والاتساق النهائي خياراً مثالياً. فعلى سبيل المثال، بُني Facebook Messenger على نظام مشابه لـ Cassandra لضمان التوافرية العالية وتقليل التأخير في الرسائل.
التجارة الإلكترونية وإدارة الجلسات
منصات التجارة الإلكترونية تُنشئ وتحدِّث المعلومات المتعلقة بالمنتجات والمستخدمين باستمرار، وتحتاج إلى القدرة على التعامل مع حمولات ذروة (Peak Loads) مثل “مواسم الأعياد” أو الجمعة السوداء. يشيع استخدام NoSQL في إدارة سلال الشراء (Shopping Carts)، وسجلات الزوار، وإدارة الجلسات، حيث يتم تخزين معلومات الجلسة في مخازن مفاتيح وقيم لتسريع الوصول.
تحليلات البيانات الضخمة
يُولّد العالم الرقمي يومياً مليارات من البيانات المتنوعة، كالرسائل النصية في تطبيقات الدردشة، وسجلات الخوادم (Logs)، ونقرات المستخدمين على صفحات الويب. تحتاج الشركات إلى منصات قوية لاستخلاص رؤى تحليلية من هذه الكمية الضخمة. تميل NoSQL إلى تقديم أداء أفضل عند التعامل مع تدفقات بيانات مستمرة وكميات مهولة، خاصة عندما تتكامل مع منصات مثل Hadoop و Apache Spark.
إنترنت الأشياء (IoT)
في تطبيقات إنترنت الأشياء، تولّد المستشعرات المنتشرة في كل مكان بيانات بشكل دائم وبأحجام كبيرة. قد تكون هذه البيانات جزئياً غير هيكلية أو متغيرة البنية مع كل تحديث في نوع المستشعر أو إصداراته. توفر NoSQL مرونة في التعامل مع هذه البنى المتغيرة، وإمكانية تخزينها وتوزيعها بشكل تلقائي على مجموعة كبيرة من العقد.
أنظمة التوصية ومحركات البحث
أنظمة التوصية، كما في خدمات البث المرئي أو مواقع التجارة الإلكترونية، تتطلب تحليلات معقدة للعلاقات بين المستخدمين والمنتجات. كثيراً ما تُستخدم أنظمة بيانية (Graph Databases) أو نظم وثائقية لتخزين هذه المعلومات. وبالنسبة لمحركات البحث، تستخدم منصات مثل Elasticsearch أو Solr لتوفير قدرات بحث نصي متقدم وفوري.
التحديات والعيوب في NoSQL
نقص المعايير القياسية
في حين تُعدّ SQL معياراً صناعيّاً لقواعد البيانات العلائقية، لا يوجد معيار واحد موحد للغات الاستعلام في NoSQL. تختلف واجهات البرمجة بشكل واضح من نظام لآخر، مما قد يزيد من صعوبة نقل التطبيقات أو تبادل المعلومات بين أنظمة مختلفة.
التنازلات في اتساق البيانات
إن تركيز العديد من أنظمة NoSQL على التوافر العالي والتوسع الأفقي قد يستلزم التضحية بالاتساق الفوري. هذا يعني أن التحديثات قد لا تظهر فوراً لكل المستخدمين، ما قد يسبب ارتباكاً في تطبيقات تتطلب اتساقاً عالي الدقة. يجب أن يراعي المطوّرون هذه النقطة جيداً قبل اختيار النظام.
المهارات والمعرفة
تعوّد الكثير من المهندسين والمطوّرين على قواعد البيانات العلائقية ولغة SQL، في حين تتطلب NoSQL منحنى تعلم جديد، وخاصة أن كل نظام لديه واجهة وأسلوب مختلف. هذا قد يؤدي إلى صعوبات في التوظيف أو التطوير لأن الكفاءات قد لا تكون منتشرة كما هو الحال في عالم SQL.
الدعم للتحليلات المعقدة
في المشاريع التي تحتاج إلى استعلامات تحليلية بالغة التعقيد (مثل عمليات JOIN المتعددة والجداول المحورية)، قد يكون تنفيذ هذه الاستعلامات صعباً أو مستحيلاً في بعض نظم NoSQL. وغالباً يحتاج المطوّرون إلى بناء حلول مخصصة أو الجمع بين NoSQL ومنصة أخرى للتحليل مثل مستودعات البيانات (Data Warehouses) التقليدية.
أفضل الممارسات لتصميم وبناء حلول NoSQL
فهم متطلبات التطبيق جيداً
يجب على المهندس تحليل حجم البيانات وطبيعتها وسرعة تدفقها والعلاقات بينها قبل اختيار أي حل NoSQL. قد يكون MongoDB مثالياً للتطبيقات المرنة التي تحتاج البحث حسب حقول متنوعة، بينما قد يكون Cassandra أو HBase مناسباً للبيانات المتدفقة بشكل ضخم مع احتياجات للكتابة المتكررة.
تحديد النمط المناسب
اختيار قاعدة بيانات بيانية لا يفيد مطلقاً إن كان التطبيق لا يحتاج فعلاً إلى استعلامات الرسم البياني المعقدة. وبالمثل، اختيار قاعدة بيانات مستندة إلى مفاتيح وقيم دون الحاجة إليها قد يجعل تطوير استعلامات التقارير صعباً. لذا، من الضروري فهم إيجابيات وسلبيات كل نمط وربطها بمتطلبات العمل.
التفكير في بنية البيانات مسبقاً
بالرغم من عدم وجود مخطط صارم في معظم نظم NoSQL، فإن العمل دون تخطيط يمكن أن يؤدي إلى فوضى يصعب إدارتها لاحقاً. لذلك يجب وضع استراتيجية واضحة حول كيفية تخزين البيانات وتنظيمها. في بعض الأحيان، يتم اتباع مبادئ مثل الدمج (Embedding) أو الربط (Referencing) في النمط الوثائقي، أو تصميم عائلات أعمدة فعّالة في النمط ذي الأعمدة العريضة.
الاهتمام بالتجزئة والنسخ
في الأنظمة الكبيرة، من الضروري تصميم أسلوب مناسب للتجزئة (Sharding) واختيار المفاتيح الأساسية (Partition Keys) بعناية لتوزيع البيانات بالتساوي عبر العقد. كما يجب اختبار استراتيجية النسخ (Replication Strategy) والتأكد من أنّها تحقق مستوى التوافر المطلوب.
مراقبة الأداء والتخطيط للسعة
تتيح NoSQL التوسع الأفقي بسهولة نسبياً، ولكن هذا لا يعني غياب الحاجة إلى المراقبة الدائمة. يجب تتبع مؤشرات الأداء الرئيسية (KPIs) مثل زمن الاستجابة، ومعدل نقل البيانات، واستخدام الموارد (CPU, Memory). كلما زاد الحمل، يمكن إضافة عقد جديدة أو إعادة توزيع الأجزاء بالشكل الأمثل.
الأمن والتحكم بالصلاحيات
بعض نظم NoSQL لم تكن في بداياتها تهتم كثيراً بالجانب الأمني مثل التحكم بالصلاحيات أو التشفير أثناء النقل. في الوقت الراهن، توفر أغلب النظم الشهيرة هذه الميزات، لكن لا بد من تفعيلها وضبطها بالشكل الصحيح. يجب أيضاً إضافة أنظمة رصد التهديدات (Intrusion Detection) وجدران حماية لتأمين البنية التحتية الموزعة.
دراسة أمثلة عملية على نظم NoSQL
MongoDB: ملك قواعد البيانات الوثائقية
المزايا الرئيسية
- سهولة التثبيت والاستخدام، وتوفر أدوات إدارة بواجهة رسومية مثل MongoDB Compass.
- دعم متكامل للاستعلام والترتيب والتجميع (Aggregation Framework).
- دعم النسخ والتجزئة المدمجين (Replication, Sharding).
حالات استخدام
مناسب لتطبيقات الويب السريعة التطور، ونماذج البيانات المتغيرة، وتطبيقات إدارة المحتوى، ومنصات التحليلات اللحظية التي لا تتطلب اتساقاً فورياً في كل لحظة.
Apache Cassandra: القوة في التوزيع والتوسع الأفقي
المزايا الرئيسية
- معمارية لامركزية (peer-to-peer) توفر قابلية توسع هائلة دون نقطة فشل وحيدة.
- اتساق نهائي (Eventual Consistency) مع قدرة التحكم في مستوى الاتساق المطلوب (Consistency Level).
- الأداء العالي في عمليات الكتابة.
حالات استخدام
منصات المراسلة الفورية (مثل التي تتطلب تخزين رسائل بلا توقف)، سجلات الأحداث، أنظمة تحليل بيانات تعمل في الوقت الفعلي، وتطبيقات الويب العالمية التي تخدم ملايين المستخدمين.
Redis: البساطة والسرعة الفائقة
المزايا الرئيسية
- تخزين في الذاكرة (In-memory) مع خيار الاستمرار على القرص.
- سرعة بالغة في العمليات، مما يجعلها مثالية لتطبيقات الزمن الحقيقي (Real-time) مثل لوحات البيانات الحية.
- دعم هياكل بيانات متقدمة كالقوائم والمجموعات والهاشيات والبت ماب (Bitmaps).
حالات استخدام
النظام المثالي لبناء آليات التخزين المؤقت (Caching)، وقوائم الانتظار (Queues)، وأنظمة التنقيط (Leaderboards). كما يمكن الاعتماد عليه كوسيط للرسائل أو تنفيذ سيناريوهات النشر/الاشتراك (Pub/Sub).
Neo4j: احتراف تحليل العلاقات
المزايا الرئيسية
- مخصص لمعالجة الرسوم البيانية المعقدة والعلاقات المترابطة بكثافة.
- لغة استعلام Cypher البسيطة والواضحة للتنقل في الرسوم البيانية وإدارة العقد والعلاقات.
- إمكانية تشغيل خوارزميات رسم بياني على البيانات بسهولة.
حالات استخدام
الشبكات الاجتماعية، أنظمة التوصية، إدارة الهوية والوصول، سلاسل التوريد، اكتشاف الاحتيال، وأي تطبيق يحتاج تحليلات متعمقة للبيانات وعلاقاتها.
جدول مقارنة مختصر بين نظم NoSQL الشهيرة
| النظام | النمط | نموذج البيانات | مستوى الاتساق الافتراضي | حالات الاستخدام |
|---|---|---|---|---|
| MongoDB | وثائق (Document Store) | JSON/BSON | اتساق فوري ضمن العقدة الأساسية | تطبيقات الويب، إدارة المحتوى، سحابات البيانات المتغيرة |
| Apache Cassandra | أعمدة عريضة (Wide-Column) | جداول ذات عائلات أعمدة | اتساق نهائي (قابل للتعديل) | البيانات المتدفقة، المراسلة الفورية، الانتشار الجغرافي الواسع |
| Redis | مفاتيح وقيم (Key-Value) | مخزن داخل الذاكرة | اتساق فوري على العقدة الأساسية | ذاكرة تخزين مؤقت، قوائم الانتظار، لوحات البيانات اللحظية |
| Neo4j | بياني (Graph) | عقد وعلاقات وخصائص | اتساق فوري في العمليات الفردية | الشبكات الاجتماعية، أنظمة التوصية، التحليلات المعقدة للعلاقات |
| Amazon DynamoDB | مفاتيح وقيم + أعمدة عريضة | جداول مرنة ونمط مفاتيح أساسية | اتساق نهائي مع خيار “اتساق قوي” | سحابي مدارة بالكامل، يدعم أحمال العمل الضخمة والتوسع التلقائي |
خطوات عملية للبدء باستخدام NoSQL
1) تحليل الاحتياجات ووضع الأهداف
قبل الشروع في تبني NoSQL، يجب على الفريق تحديد أهداف واضحة: هل الهدف زيادة الأداء؟ أم التعامل مع بنى بيانات مرنة؟ أم التوسع الجغرافي؟ يساعد هذا التحليل في اختيار النظام الملائم واستراتيجية التنفيذ الصحيحة.
2) اختيار النمط أو قاعدة البيانات الملائمة
اعتماداً على طبيعة البيانات وحجمها والعلاقات بينها، تتم المفاضلة بين النظام الوثائقي أو المفاتيح والقيم أو البياني أو الأعمدة العريضة. كما يمكن الجمع بين أكثر من نظام في بنية هجينة إذا كانت التطبيقاته متعددة المتطلبات.
3) تصميم نموذج البيانات
مهما كان النظام المختار، لا بد من وضع تصور للنموذج المناسب للبيانات. في MongoDB مثلاً، يتم تحديد كيف سيتم تضمين (Embed) البيانات في وثيقة واحدة، ومتى يجب استخدام المراجع (References) لفصل الوثائق. في Cassandra يتم اختيار المفتاح الأساسي (Primary Key) وتجزئة البيانات بما يضمن توزيعاً متوازناً.
4) تهيئة البنية التحتية
يمكن نشر أنظمة NoSQL إما على خوادم محلية أو في السحابة أو كحل مُدار من مزودين مثل AWS أو Azure. يتطلب ذلك ضمان متطلبات الشبكة والتخزين ووجود خطط نسخ احتياطي (Backup) واستعادة (Recovery) واضحة.
5) التطوير والاختبارات
خلال مرحلة التطوير، تُختبر واجهة برمجة التطبيقات (API) وخوارزميات الوصول. ينبغي القيام باختبارات تحميل (Load Testing) ومحاكاة أحمال العمل الفعلية. هذا يكشف عن أية عنق زجاجة محتملة في الأداء أو قضايا في التصميم.
6) الإطلاق والمراقبة
بعد نجاح الاختبارات، ينطلق النظام في مرحلة الإنتاج. هنا تأتي أهمية المراقبة المستمرة للأداء والاستخدام. يمكن الاستعانة بأدوات مثل Grafana و Prometheus لمراقبة مؤشرات النظام، مع وضع إنذارات تلقائية عند تجاوز بعض العتبات.
تلخيص
هي قواعد بيانات (Not Only SQL) أي “ليست SQL” أو “غير علائقية”، وهي عكس ما عرفناه من قواعد البيانات SQL، سواءً SQLlite أو MySQL أو SQL Server.
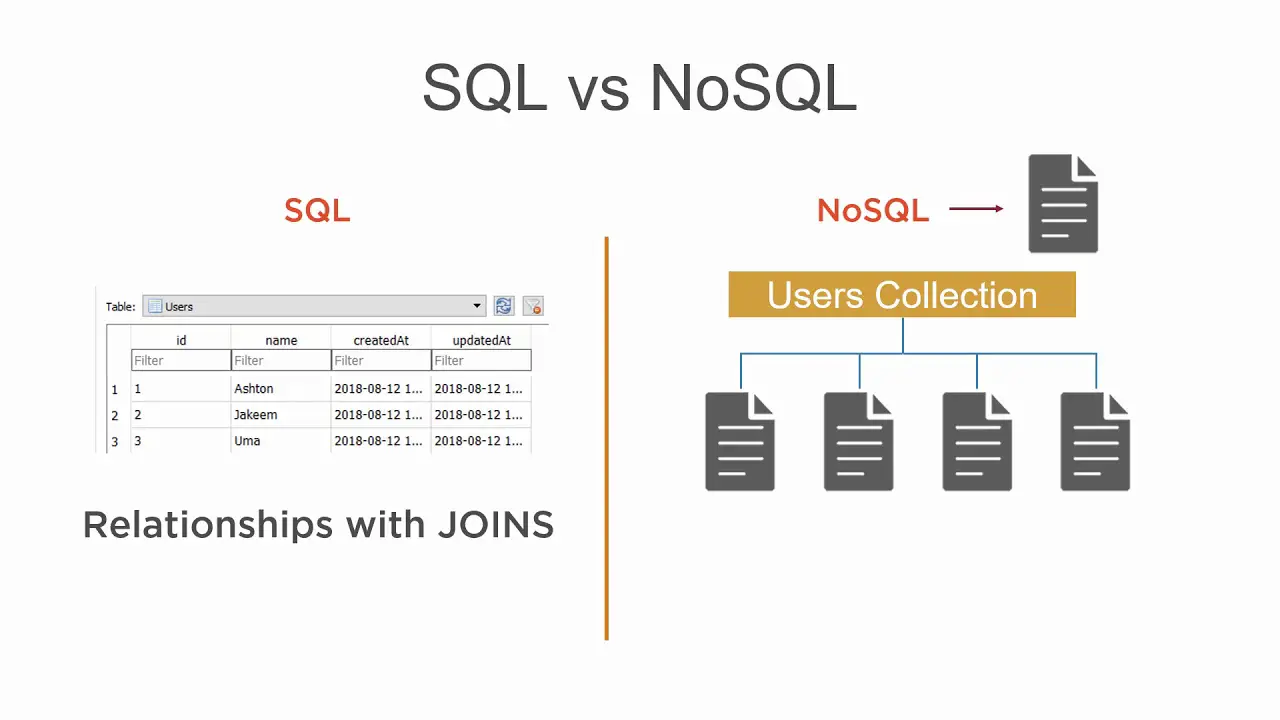 انتشرت قواعد بيانات NoSQL مع انتشار مفهوم البيانات الضخمة “Big Data” والتي لم يكن من الممكن التعامل معها باستخدام الطريقة التقليدية في حفظ واسترجاع البيانات عن طريق قواعد البيانات العلائقية Relational” Databases”، لهذا جاءت هته التقنية الجديدة من أجل حل المشاكل الجديدة التي ظهرت معها.
انتشرت قواعد بيانات NoSQL مع انتشار مفهوم البيانات الضخمة “Big Data” والتي لم يكن من الممكن التعامل معها باستخدام الطريقة التقليدية في حفظ واسترجاع البيانات عن طريق قواعد البيانات العلائقية Relational” Databases”، لهذا جاءت هته التقنية الجديدة من أجل حل المشاكل الجديدة التي ظهرت معها.
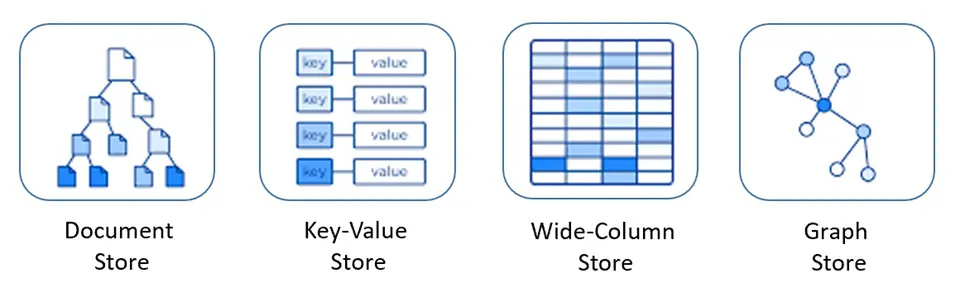
تقنية NoSQL توفر آلية لتخزين واسترجاع البيانات التي تم تصميمها بتقنيات أو طرق غير العلاقات المجدولة المستخدمة في قواعد البيانات العلائقية حيث يُتيح حرية وديناميكية أكثر في تصميم قواعد البيانات، إضافةً إلى أنها مصممة لتحتاج أقل إدارة وصيانة.
أهم مميزات قواعد البيانات NoSQL :
- تقوم بتخزين البيانات في ملفات (Documents) عوض تخزينها في جداول (Tables).
- لا تَتَّبع تصميم ثابت (Schema) كما في SQL.
- تدعم التوسع وإتاحة البيانات في جميع الأوقات بشكل ممتاز (Performance and Availability).
- مخصصة للتعامل مع البيانات الضخمة.
- مخصصة للتطبيقات التي تتطلب حجماً كبيرًا للبيانات، وزمن وصول منخفض.
- السرعة في حفظ واسترجاع البيانات.
نصائح ختامية
- لا يعني تبنّي NoSQL التخلي التام عن قواعد البيانات العلائقية. في الكثير من السيناريوهات، يعمل الاثنان جنباً إلى جنب في بيئة واحدة.
- احرص على فهم نموذج الاتساق الذي يقدمه النظام المختار. قد يكون بعض التطبيقات حساساً جداً للتأخير في اتساق البيانات.
- صمّم سعة التخزين وحجم العقد (Nodes) بناءً على أحمال العمل المتوقعة. التوسع الأفقي لا يعني بالضرورة إضافة عشرات العقد دون دراسة.
- استفد من مجتمع المستخدمين والوثائق الرسمية لكل نظام قبل اتخاذ قرار التصميم.
خلاصة شاملة
استطاعت قواعد البيانات NoSQL أن تُحدِث نقلة نوعية في طرق تخزين البيانات وإدارتها، في وقت لم تعد فيه النظم التقليدية تفي بمتطلبات التوسع والأداء لدى كبرى شركات التقنية. بفضل المرونة الكبيرة في الهياكل (المفاتيح والقيم، الوثائق، الأعمدة العريضة، الرسوم البيانية) وإمكانية التوزيع الجغرافي والاتساق النهائي، أصبحت NoSQL خياراً جذاباً لتطبيقات الويب الضخمة، وتحليلات البيانات الضخمة، وإنترنت الأشياء، وغيرها من المجالات التي تتطلب معالجة سريعة لكمّ هائل من البيانات.
مع ذلك، يجب اختيار النظام المناسب بناءً على تحليل عميق لاحتياجات المشروع. فمن جهة، تتميّز القواعد العلائقية بالنضج والتماسك الفوري، ومن جهة أخرى، تقدم NoSQL مرونة وقابلية للتوسع. وفي كثير من الأحيان، يفضل استخدام مزيج من التقنيات لتحقيق أفضل النتائج. في نهاية المطاف، يمكن القول إنّ NoSQL ليست بديلاً كاملاً للعلائقية، بل هي توسع للأدوات المتاحة للمطوّرين والمهندسين للتعامل مع سيناريوهات العالم الواقعي التي تتطلب تنوعاً في نماذج البيانات وسرعة في النمو.
المراجع والمصادر
- Stonebraker, M., & Cattell, R. (2011). “10 rules for scalable performance in ‘simple operation’ datastores.” Communications of the ACM.
- Brewer, E. (2012). “CAP twelve years later: How the ‘rules’ have changed.” Computer, 45(2), 23–29.
- Amazon Web Services. “Amazon DynamoDB Documentation.” https://docs.aws.amazon.com/dynamodb/
- MongoDB Inc. “MongoDB Documentation.” https://docs.mongodb.com/
- Apache Cassandra. “Cassandra Documentation.” https://cassandra.apache.org/doc/latest/
- Redis Labs. “Redis Documentation.” https://redis.io/documentation
- Neo4j. “Neo4j Documentation.” https://neo4j.com/docs/
- Hbase. “Apache HBase Documentation.” https://hbase.apache.org/book.html
- Leavitt, N. (2010). “Will NoSQL databases live up to their promise?” Computer, 43(2), 12–14.
- Cattell, R. (2011). “Scalable SQL and NoSQL data stores.” SIGMOD Record 39(4), 12–27.