الذكاء الصنعي أو تقنيةُ التعلُّم التجمُّعي (Ensemble Learning)
مقدّمة
تُمثِّل تقنيةُ التعلُّم التجمُّعي (Ensemble Learning) إحدى أهمّ ركائز الذكاء الاصطناعي الحديث؛ إذ تجمعُ بين قوّةِ عدّة نماذج فرعيّة لتحسين الدقّة، والموثوقيّة، وقابلية التعميم. تقوم الفكرة المركزيّة على افتراضٍ بديهيّ مفاده أنّ «حُكمَ الجماعة أصوبُ من رأي الفرد»؛ فكما يَعتمِدُ الإنسانُ على لجنةٍ من الخبراء لاتّخاذ قرارٍ مصيريّ، يعتمدُ النظامُ الذكيّ على مجموعة نماذج تشاركيّة تتقاطع أخطاؤها فتُقلِّل التباين والتحيّز معًا. يُعدّ هذا الأسلوب امتدادًا لمنطق «المتوسّط المُرجَّح» ولكن بصيغةٍ إحصائيّةٍ معقّدة ترنو إلى الوصول إلى حدِّ التعميم المثاليّ لنموذجٍ نظريّ غير مُقيَّد.
1. الجذور التاريخيّة للتعلُّم التجمّعي
- الستينيات والسبعينيات: ظهرت البواكير الأولى في بحوث الإحصاء حول «المصوِّتات المُجمّعة» (Condorcet Jury Theorem) وتحليل أخطاء المُصنِّفين البسيطة كوسيلة لقياس الجودة المتوقّعة بعد الدمج.
- الثمانينيات: طوّر مؤتمر NIPS الأساسيّ نقاشات حول خفض التباين والتحيّز عبر تجميع نماذج الانحدار الخطيّ.
- التسعينيات: صاغ Breiman خوارزمية Bagging (1994) ثمّ Random Forest (2001)، بينما طوّر Schapire و Freund خوارزمية AdaBoost (1996) التي رسَّخت مفهوماً جديداً للوزن التكيّفيّ.
- الألفيّة الجديدة: شهدت انفجار خوارزميات Gradient Boosting وصولاً إلى XGBoost (2016)، ومن بعدها LightGBM و CatBoost، قبل أن تنتقل الفكرة إلى الشبكات العميقة عبر Deep Ensembles و«نماذج اللقطة» (Snapshot Ensembles).
2. الدوافع النظريّة
2.1 التحيّز مقابل التباين
- التحيّز (Bias): خطأ منهجيّ ناتج عن بساطة النموذج.
- التباين (Variance): حساسيّة النموذج تجاه تقلب عيّنات التدريب.
التعلّم التجمُّعي يُقلّل التباين غالباً، وقد يُقلّل التحيّز إذا ضُمَّنت نماذج ذات هياكل متنوّعة.
2.2 شرط التنوّع
لا يُجدي تجميعُ نماذج متطابقة؛ يجب أن تُظهر اختلافات جوهريّة في أخطائها. يُقاس التنوّع عبر:




- مصفوفة الارتباط بين المتوقّعات.
- مقياس Q الإحصائيّ.
- نسبة الاتفاق المتبادل.
3. التصنيفات الرئيسة لخوارزميات Ensemble
| الفئة | الآليّة | أشهر الخوارزميات | ملاحظات تطبيقية |
|---|---|---|---|
| Bagging | تدريب نماذج متوازية على عينات مُعيدة (Bootstrap) ثم أخذ متوسّط أو تصويت | Random Forest، Extra Trees | يخفض التباين، قابل للتوزيع الأفقي |
| Boosting | تدريب تسلسلي؛ كل نموذج يُركِّز على أخطاء سابقيه | AdaBoost، Gradient Boosting، XGBoost، LightGBM، CatBoost | يقلّل التحيّز، الحساسيّة للضجيج أعلى |
| Stacking | ميتا-متعلِّم يدمج مخرجات نماذج قاعدة متباينة | Blending، Super Learner | أقوى أداءً لكن أكثر تعقيداً |
| Voting & Averaging | دمج مباشر للاحتمالات أو الأصوات | Soft/Hard Voting | بسيط، يُستخدم أساساً كخط أساس |
| Deep Ensembles | نماذج شبكات عصبيّة عميقة مُبتدأتها عشوائيّة مختلفة | Snapshot Ensemble، SWA | يعالج عدم اليقين في التعلّم العميق |
4. تحليل رياضي مُبسَّط
- نظرية بايز تبرهن أن المزج الخطيّ المُرجَّح لمقدِّرات شرطية مستقلة يُحسِّن قيمة الاحتمال البَعدي.
- حدّ تشيبشيف يؤكّد أنّ متوسّط M نماذج مستقلّة ينخفض تباينه بنسبة 1/M1/M.
- مبرهنة الاستقرار: في مساحة فرضيات ذات سعة VC ثابتة، يمكن لأسلوب التجمُّع أن يوسّع الحدود العامة (generalization bounds) عبر ضبط «نصف القطر ρ» للتوزيعة الفعليّة للأخطاء.
5. خطوات بناء تجمُّع فعّال
- اختيار النماذج الأساسيّة: أشجار قرار، شبكات عصبيّة، انحدار لوغستي، إلخ.
- تحقيق التنوّع:
- الحقن بالضوضاء (Noise Injection).
- تغيرات بيانات (Data Augmentation).
- اختيارات خصائص فرعيّة (Feature Subsampling).
- آلية الدمج: متوسّط مرجّح، تصويت أغلبيّة، ميتا-متعلِّم.
- ضبط الأوزان: عبر خوارزميات مثل Gradient Optimization أو Bayesian Model Averaging.
- قياس الأداء: استخدام مقاييس F1، AUC، Log-Loss، مع تحليل منحنيات Bias-Variance.
6. تطبيقات عمليّة متقدّمة
- الرؤية الحاسوبيّة: تجميع الشبكات التلافيفيّة لرفع دقّة كشف الأجسام في أنظمة القيادة الذاتيّة.
- معالجة اللغة الطبيعيّة: دمج مخرجات نماذج Transformer مع RNN في الترجمة الآليّة الفورية لتقليل الأخطاء السياقيّة.
- التنبؤ المالي: تجميع أشجار Gradient Boosting مع شبكات LSTM لتوقّع تقلبات أسعار الأسهم اليوميّة.
- الكشف عن الاحتيال: استخدام Random Forest مع Autoencoders لاكتشاف أنماط شاذّة في معاملات بطاقات الائتمان.
- الطبّ الحيويّ: دمج مصنفات تصوير شعاعي مع بيانات جينوميّة لتحسين تشخيص السرطان المبكّر.
7. التحدّيات والأفخاخ الشائعة
- استنزاف الموارد: يزداد استهلاك الذاكرة والزمن الخطيّياً بعدد النماذج.
- خطر الإفراط في الملاءمة عند Boosting على بيانات صغيرة أو ضوضائيّة.
- تعقيد قابلية الشرح: يصعب شرح قرار التجمّع مقارنة بنموذجٍ فرديّ، خصوصاً في القطاعات شديدة الحساسيّة كالرعاية الصحّيّة.
- إدارة خطّ الأنابيب: الحاجة إلى بنيّة تحتية أوتوماتية (MLOps) لضمان تحديث كل نموذج فرعيّ دورياً.
8. الاتجاهات البحثيّة الحديثة
- Distillation Ensembles: ضغط التجمّع في نموذجٍ واحد يُدعى «طالب» يحتفظ بمعظم المنافع.
- Bayesian Deep Ensembles: دمج مبدأ MC Dropout مع تجمع شبكات مستقلّة لقياس عدم اليقين الكمّي.
- Ensemble NAS: استخدام البحث العصبيّ التلقائي لاختيار بنى شبكات متنوّعة تلقائياً قبل التجمّع.
- الاتحاد مع التعلّم الموزّع (Federated Ensembles) لتجميع نماذج متدرَّبة محليّاً دون مشاركة البيانات الخام حمايةً للخصوصية.
9. دروس عمليّة وخلاصة توصيات
- حقق التوازن بين التنوّع والدقّة؛ فالنموذج الضعيف جداً لا يُضيف قيمة حتى لو كان مختلفاً.
- راقب مؤشّر Out-of-Bag Error في Bagging لتقدير أداء التجمّع دون تقسيم بيانات إضافيّة.
- في التطبيقات الصناعيّة الفوريّة، استعمل LightGBM لأنه يوازن بين السرعة والأداء وكفاءة الذاكرة.
- لا تُهمل «تصفية الخصائص» (Feature Pruning) بعد التدريب؛ فقد تجد أنّ عدداً قليلاً من النماذج الفرعية يوفّي بالغرض.
- اجعل عملية الدمج والمراقبة جزءاً من مسار MLOps حتى لا يتحوّل النظام إلى «وحشٍ» يصعُبُ صيانته.
خاتمة
يُبرهنُ التعلّمُ التجمُّعيّ أنّ الذكاء الاصطناعي لا يتعلّق بقوّة نموذجٍ فرديّ بقدر ما يتعلّق بقدرة الباحث على تنسيق «جوقة» نماذج تؤدّي بانسجامٍ وتكامل. ومع استمرار تزايد أحجام البيانات وتعقيد المشكلات الواقعيّة، تصبحُ الحاجةُ إلى استراتيجياتٍ تقلّل المخاطر وتزيد الدقّة أكثر إلحاحاً. Ensemble Learning يوفّر لنا إطاراً متيناً يستلهم فكرة الحكمة الجماعيّة في بيئة حسابيّة، مُمهِّداً الطريق أمام أنظمة أكثر استقراراً وموثوقيّةً وقدرةً على التعامل مع شتى السيناريوهات المُستقبليّة.
ملخص
ما هي تقنية الذكاء الصنعي التي يطلق عليها التعلم الجمعي أو الـ Ensemble learning ؟
يُحكى أنه في الألفية الأولى قبل الميلاد وفي شبه القارة الهندية تحديداً جيءَ بفيل ضخم و ستة عُميان إلى حاكم البلدة الذي سمح لهم بلمس هذا المخلوق الذي يُسمونه الفيل ولا يعرفون شيءً عن شكله لكنه اشترط عليهم بالمقابل أن يصفوه في جملة واحدة .. بعد تفحص الفيل قرر أول العميان أنه الفيل أشبه ما يكون بالأفعى وقال الثاني بل هو كالجدار والثالث كان متأكداً تماما بأن الفيل يماثل نوعاُ من الأشجار ! أما باقي العميان فلكل رأيه هو الآخر !
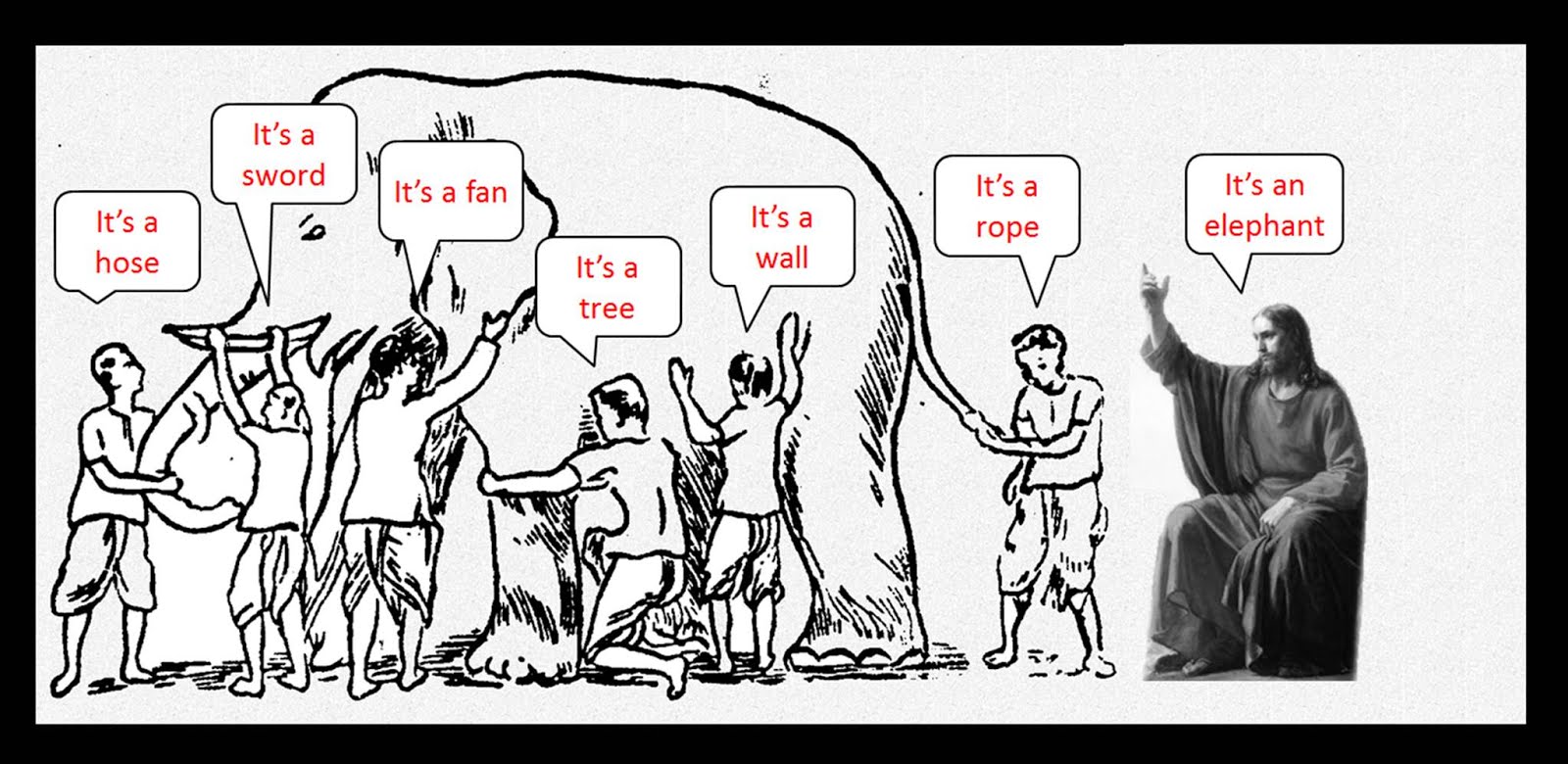
على مر التاريخ اُستخدمت هذه القصة لتصوير العديد من الحقائق و المغالطات التي تعتري المعارف والتجارب الفردية ، من هذا المنطلق تم تعريف التعلم الجمعي أو الـ Ensemble learning وبدأ استخدامه في الذكاء الصنعي كركيزة قوية لتحسين عملية التعلم والوصول الى نماذج قوية حيث أن العميان في الأمثولة كان لكل منهم تجربة فردية محدودة والوصول الى الحقيقة يتطلب الجمع بين كل هذه التجارب الجزئية عبر طرق تسمى الـ Ensemble methods .
الـ Ensemble methods في تعلم الآلة هي طرق الجمع بين خوارزميات التعلم المختلفة بحيث تدعم كل خوارزمية أختها في سبيل تقوية عملية التنبوء (prediction)
وأشهر هذه الطرق تجزئة النموذج الى مجموعة من أشجار القرار الصغيرة (decision trees classifiers) والغابات العشوية المصغرة بإعتماد المبدأ الأساسي الذي يقول أن مجموعة من مصنفات القرار الضعيفة تتصرف أقوى من مصنف قرار واحدة كبير ؛ باختصار فإن عملية التعلم الجمعي تتم عبر تقسيم نموذج الذكاء الصنعي الى مجموعة من النماذج الصغيرة في عملية التعلم ثم تحويلها إلى نموذج واحد قوي قبل مرحلة التنبوء ويتم اعتماد تقنيات تقييم وتصويت تسمى الخوارزميات الجينية (genetic algorithms) في هذه العملية للتخلص من النماذج التي تُضعف عملية التنبوء ( البقاء للاصلح او الاقوى ) .



