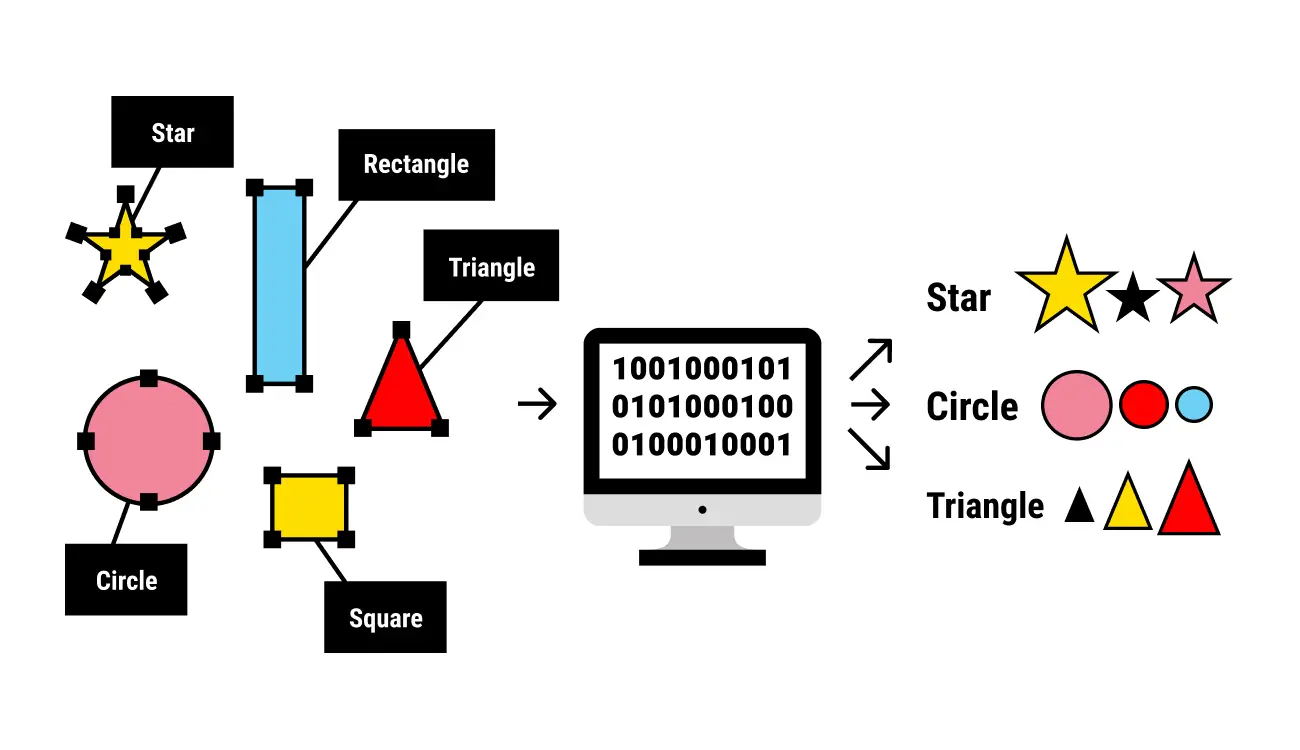
تسمية البيانات
ما هي تسمية البيانات؟ What Is Data Labeled ؟
في التعلم الآلي، تعتبر تسمية البيانات (Labeling)هي عملية تحديد البيانات الخام فيما اذا كانت صور اوالملفات النصية المقاطع الفيديو …الخ وإضافة التسميات التعريفية لكل صورة الغرض منها توفير سياق بحيث يمكن لنموذج التعلم الآلي التعلم منه على سبيل المثال، قد تشير الصور إلى ما إذا كانت الصورة تحتوي على طائر أو سيارة، او ما هي الكلمات التي تم نطقها في تسجيل صوتي، أو ما إذا كانت الأشعة السينية (X-Ray) تحتوي على ورم Tumor
تصنيف البيانات مطلوب لمجموعة متنوعة من حالات الاستخدام بما في ذلك رؤية الكمبيوتر (Computer Vision) ومعالجة اللغة الطبيعية NLP



كيف يعمل تصنيف البيانات (How Does Data Labeling Work)
اليوم، تستخدم معظم نماذج التعلم الآلي العملية التعلم الخاضع للإشراف(Supervised Learning)، والذي يطبق خوارزمية لتعيين مدخل واحد لمخرج واحد (Algorithm To Map One Input To One Output). لكي يعمل التعلم الخاضع للإشراف (Supervised Learning)، تحتاج إلى مجموعة مصنفة (Labeled Set Of Data) من البيانات يمكن للنموذج التعلم منها لاتخاذ القرارات الصحيحة. (Make Correct Decision)
يبدأ تصنيف البيانات (Data Labeling) عادةً بمطالبة البشر بإصدار أحكام حول جزء معين من البيانات غير المسماة (Unlabeled Data).
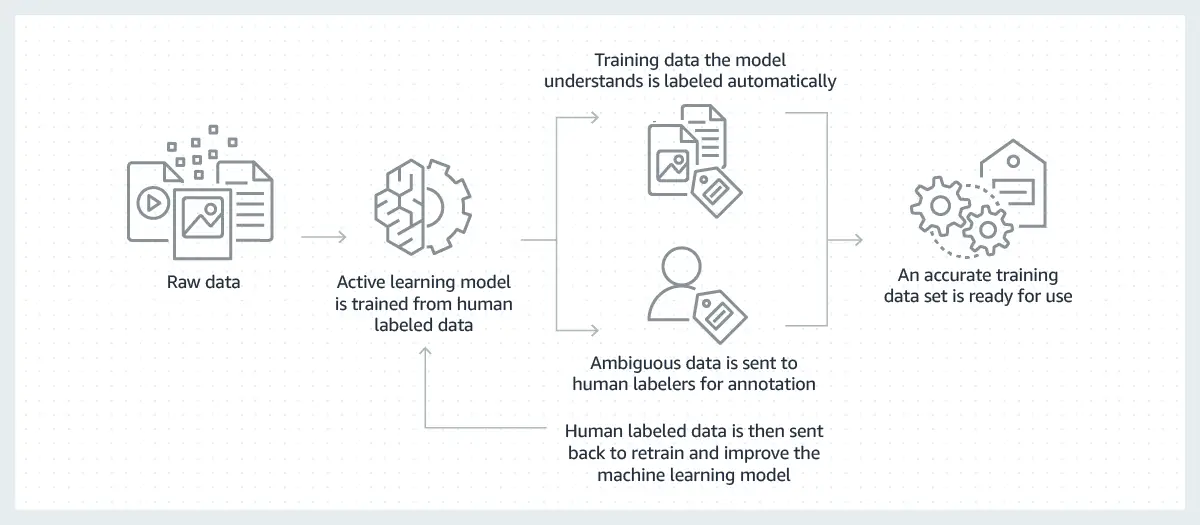
على سبيل المثال، قد يُطلب من القائمين على الملصقات وضع علامة على جميع الصور في مجموعة بيانات حيث تكون عبارة “هل تحتوي الصورة على طائر” صحيحة. يمكن أن تكون العلامات قاسية مثل نعم / لا بسيطة أو محببة مثل تحديد وحدات البكسل المحددة في الصورة المرتبطة بالطائر. يستخدم نموذج التعلم الآلي الملصقات التي يوفرها الإنسان لتعلم الأنماط الأساسية في عملية تسمى “تدريب النموذج”(Underlying Patterns) والنتيجة هي نموذج مدرب (Model Training) يمكن استخدامه لعمل تنبؤات بشأن البيانات الجديدة (Predictions On New Data). في التعلم الآلي، غالبًا ما تسمى مجموعة البيانات المصنفة بشكل صحيح والتي تستخدمها كمعيار موضوعي لتدريب وتقييم نموذج معين “الحقيقة الأساسية”(Ground Truth)
ما هي بعض الأنواع الشائعة لتصنيف البيانات (Data Labeling)؟
الرؤية الحاسوبية (Computer Vision)
عند إنشاء نظام رؤية الكمبيوتر ، تحتاج أولاً إلى تسمية الصور أو البكسل أو النقاط الرئيسية ، أو إنشاء حد يحيط بشكل كامل صورة رقمية ، تُعرف باسم الصندوق المحيط (Bounding Box)، لإنشاء مجموعة بيانات التدريب الخاصة بك (Training Dataset).
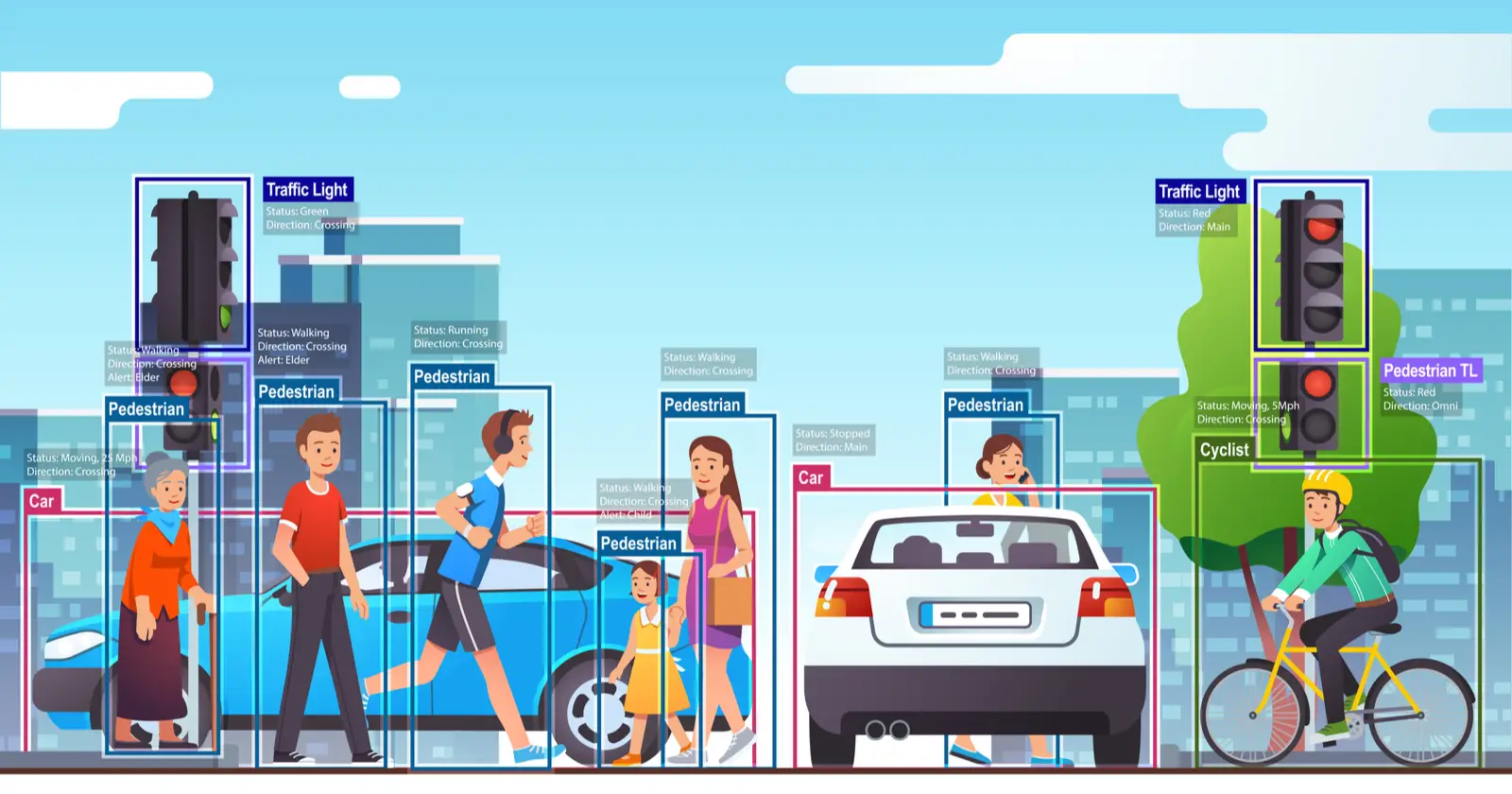
على سبيل المثال ، يمكنك تصنيف الصور حسب نوع الجودة (مثل صور المنتج مقابل صور نمط الحياة) أو المحتوى (ما هو موجود بالفعل في الصورة نفسها) ، أو يمكنك تقسيم الصورة على مستوى البكسل. يمكنك بعد ذلك استخدام بيانات التدريب هذه لبناء نموذج رؤية كمبيوتر يمكن استخدامه لتصنيف الصور(Categorize Images) تلقائيًا أو اكتشاف موقع الكائنات (Detect The Location Of Objects) أو تحديد النقاط الرئيسية في الصورة أو تقسيم الصورة(Segment An Image)
معالجة اللغة الطبيعية (Natural Language Processing)
تتطلب معالجة اللغة الطبيعية أولاً تحديد أقسام مهمة من النص يدويًا أو تمييز النص باستخدام تسميات محددة لإنشاء مجموعة بيانات التدريب الخاصة بك. على سبيل المثال ، قد ترغب في تحديد الشعور أو القصد من دعاية نصية ، وتحديد أجزاء من الكلام ، وتصنيف الأسماء المناسبة مثل الأماكن والأشخاص ، وتحديد النص في الصور أو ملفات Pdf أو الملفات الأخرى.
 للقيام بذلك ، يمكنك رسم مربعات إحاطة حول النص ثم نسخ النص يدويًا في مجموعة بيانات التدريب الخاصة بك. تُستخدم نماذج معالجة اللغة الطبيعية لتحليل المشاعر(Sentiment Analysis) ، والتعرف على اسم الكيان(Entity Name Recognition) ، والتعرف البصري على الأحرف(Optical Character Recognition)
للقيام بذلك ، يمكنك رسم مربعات إحاطة حول النص ثم نسخ النص يدويًا في مجموعة بيانات التدريب الخاصة بك. تُستخدم نماذج معالجة اللغة الطبيعية لتحليل المشاعر(Sentiment Analysis) ، والتعرف على اسم الكيان(Entity Name Recognition) ، والتعرف البصري على الأحرف(Optical Character Recognition)
معالجة الصوت (Audio Processing)
تقوم المعالجة الصوتية بتحويل جميع أنواع الأصوات مثل الكلام، وضوضاء الحياة البرية (النباح، والصفارات، أو الزقزقة)، وأصوات البناء (كسر الزجاج ، أو عمليات المسح ، أو الإنذارات) إلى تنسيق منظم بحيث يمكن استخدامه في التعلم الآلي.
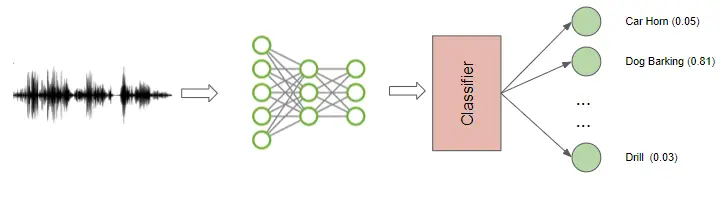 غالبًا ما تتطلب منك معالجة الصوت أولاً نسخها يدويًا إلى نص مكتوب. من هناك، يمكنك الكشف عن معلومات أعمق حول الصوت عن طريق إضافة العلامات وتصنيف الصوت. يصبح هذا الصوت المصنف مجموعة بيانات التدريب الخاصة بك (Training Dataset)
غالبًا ما تتطلب منك معالجة الصوت أولاً نسخها يدويًا إلى نص مكتوب. من هناك، يمكنك الكشف عن معلومات أعمق حول الصوت عن طريق إضافة العلامات وتصنيف الصوت. يصبح هذا الصوت المصنف مجموعة بيانات التدريب الخاصة بك (Training Dataset)