لعرض مصفوفة الالتباس (Confusion Matrix) في R باستخدام ggplot2، يمكنك استخدام الدالة geom_tile() لرسم مربعات اللون الملونة التي تمثل قيم المصفوفة. يمكنك أيضًا استخدام facet_grid() أو facet_wrap() لتقسيم الرسم البياني إلى لوحات فرعية تمثل الطرق المختلفة.
قم بتجميع البيانات الخاصة بالطرق المختلفة وقم بإنشاء الرسم البياني كما يلي:
Rlibrary(ggplot2)
# بيانات المصفوفة لكل طريقة
dframe <- structure(list(label = structure(c(4L, 2L, 1L, 3L, 4L, 2L, 1L, 3L), .Label = c("fn", "fp", "tn", "tp"), class = "factor"), value = c(9, 0, 3, 1716, 6, 3, 6, 1713), method = structure(c(1L, 1L, 1L, 1L, 2L, 2L, 2L, 2L), .Label = c("method1", "method2"), class = "factor")), .Names = c("label", "value", "method"), row.names = c(NA, -8L), class = "data.frame")
# إنشاء الرسم البياني
ggplot(dframe, aes(x = label, y = method, fill = value)) +
geom_tile(color = "white") +
scale_fill_gradient(low = "white", high = "steelblue") +
labs(x = "Actual", y = "Method", fill = "Value") +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
facet_wrap(~ method, scales = "free_y")
تُظهر هذه الشفرة البرمجية مصفوفة الالتباس بالألوان حيث يُظهر لون كل خلية قيمتها. تستخدم scale_fill_gradient() لتحديد مدى التدرج للألوان، وfacet_wrap() لتقسيم الرسم البياني إلى لوحات فرعية لكل طريقة.
المزيد من المعلومات

بالطبع! يُستخدم تمثيل البيانات بواسطة مصفوفة الالتباس (Confusion Matrix) في مجالات عديدة مثل تقييم أداء نماذج التصنيف في تعلم الآلة وتقييم النظم الذكية. تعتبر المصفوفة مفيدة لفهم أداء النموذج من حيث عدد النتائج الصحيحة والخاطئة التي يتنبأ بها النموذج.
تتكون مصفوفة الالتباس من أربع خلايا رئيسية:
- True Positives (TP): عدد العينات التي تم تصنيفها بشكل صحيح كإيجابيات.
- False Positives (FP): عدد العينات التي تم تصنيفها بشكل غير صحيح كإيجابيات.
- True Negatives (TN): عدد العينات التي تم تصنيفها بشكل صحيح كسلبيات.
- False Negatives (FN): عدد العينات التي تم تصنيفها بشكل غير صحيح كسلبيات.
من خلال تحليل مصفوفة الالتباس، يمكننا حساب عدة مقاييس لأداء النموذج مثل الدقة (Accuracy)، الاستدعاء (Recall)، الدقة الإيجابية (Precision)، ومعدل الخطأ النوعي (False Positive Rate).
الدقة (Accuracy) تُعرف بنسبة العينات الصحيحة (TP و TN) من إجمالي العينات. الاستدعاء (Recall) هو نسبة العينات الإيجابية الصحيحة (TP) من مجموع العينات الإيجابية الحقيقية (TP و FN). الدقة الإيجابية (Precision) هي نسبة العينات الإيجابية الصحيحة (TP) من مجموع العينات المصنفة كإيجابيات (TP و FP). أما معدل الخطأ النوعي (False Positive Rate) فهو نسبة العينات السلبية الخاطئة (FP) من مجموع العينات السلبية الحقيقية (TN و FP).
إذا كان لديك أي أسئلة أو استفسارات إضافية، فلا تتردد في طرحها!
 في كل مرة تستخدم فيها محرك البحث أحد أهم الأسباب التي تجعل تلك المحركات تعمل بشكل جيد هي خوارزميات الـ Machine Learning؛ تجعل شركة Google وغيرها من محركات البحث الأخرى هذه الخوارزميات تقوم بتصنيف وترتيب الصفحات وظهور النتائج بشكل جيد.
في كل مرة تستخدم فيها محرك البحث أحد أهم الأسباب التي تجعل تلك المحركات تعمل بشكل جيد هي خوارزميات الـ Machine Learning؛ تجعل شركة Google وغيرها من محركات البحث الأخرى هذه الخوارزميات تقوم بتصنيف وترتيب الصفحات وظهور النتائج بشكل جيد.

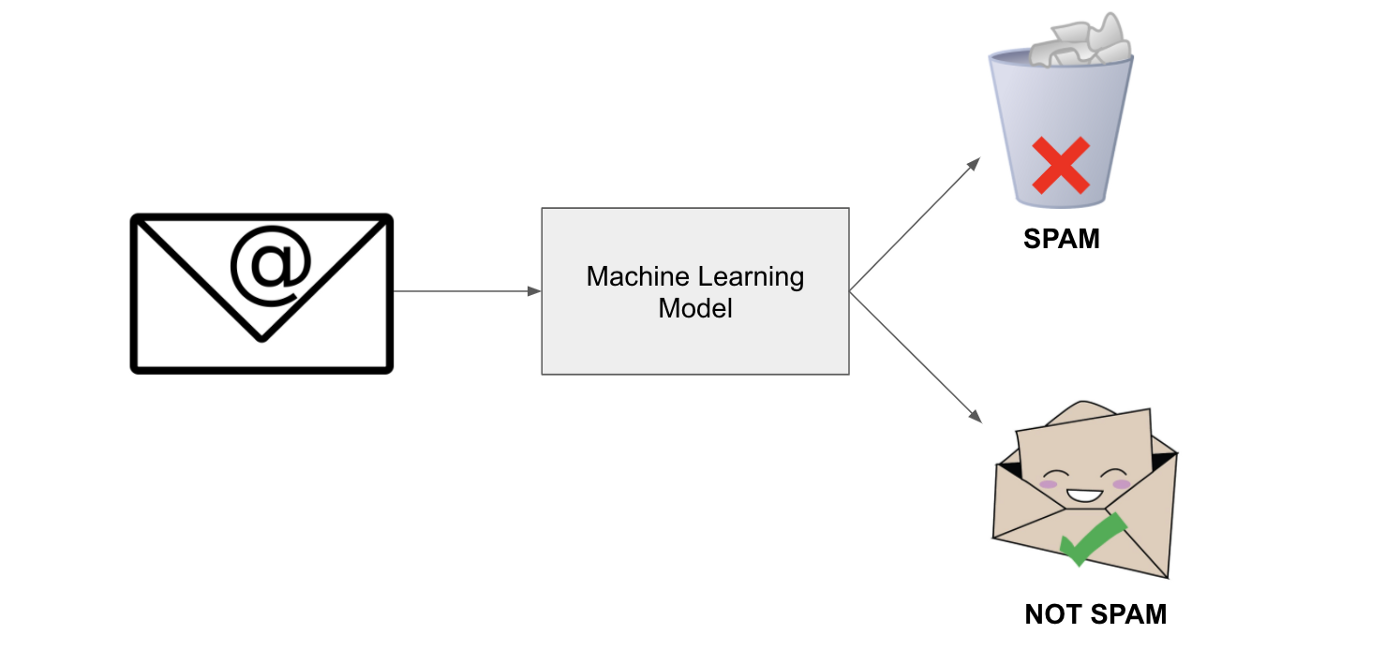
 تعتمد الخوارزميات المستخدمة في تعلم الآلة على مجموعة من النمادج الرسومية وأدوات القرار، كمعالجة اللغات الطبيعية والشبكات العصبية الاصطناعية للقيام بمهمة أتمتة البيانات المحللة والمعالجة، وبالتالي تحفيز الآلة على اتخاذ القرار والقيام بالمهام الموكلة لها بكل سهولة؛ ولابد من الإشارة إلى أن الشبكات العصبية الاصطناعية المستخدمة في تعلم الآلة تُؤدّي دوراً في غاية الأهمية يُضاهي دور الأعصاب وشبكاتها في جسم الإنسان ودماغه؛ وانطلاقاً من الدور المعقد الذي تقوم به الخوارزميات وأدواتها، فقد ظهرت الحاجة إلى الملحة للإتيان بما يُعرف بــ “التعلم العميق Deep Learning”.
تعتمد الخوارزميات المستخدمة في تعلم الآلة على مجموعة من النمادج الرسومية وأدوات القرار، كمعالجة اللغات الطبيعية والشبكات العصبية الاصطناعية للقيام بمهمة أتمتة البيانات المحللة والمعالجة، وبالتالي تحفيز الآلة على اتخاذ القرار والقيام بالمهام الموكلة لها بكل سهولة؛ ولابد من الإشارة إلى أن الشبكات العصبية الاصطناعية المستخدمة في تعلم الآلة تُؤدّي دوراً في غاية الأهمية يُضاهي دور الأعصاب وشبكاتها في جسم الإنسان ودماغه؛ وانطلاقاً من الدور المعقد الذي تقوم به الخوارزميات وأدواتها، فقد ظهرت الحاجة إلى الملحة للإتيان بما يُعرف بــ “التعلم العميق Deep Learning”.