عندما تقوم ببناء نموذج باستخدام مكتبة Keras، فإن الإخراج الذي تراه يمثل تقريراً مفصلاً عن تدريب النموذج. لفهم معنى الـ”epoch” والـ”loss” في Keras، يجب أن نتناول هذا التقرير بشكل أكثر تفصيلاً.
أولاً وقبل كل شيء، يُعرف الـ”epoch” بأنه دورة كاملة لجميع البيانات التدريبية تمر عبر النموذج. في كل “epoch”، يقوم النموذج بتحديث وزنه بناءً على الفروق بين النتائج التي يتنبأ بها والنتائج الفعلية.
أما الـ”loss”، فيُمثل هذا المصطلح قيمة دالة الخسارة التي تقيس مقدار الخطأ بين التوقعات التي أنتجها النموذج والقيم الفعلية للبيانات التدريبية. يهدف الهدف من التدريب إلى تقليل قيمة الـ”loss”، أي تقليل الخطأ بحيث يكون أداء النموذج أفضل.
في التقرير الذي قدمته، يظهر لنا النموذج قيم الـ”loss” لكل “epoch” من 1 إلى 20. يمكن أن نرى كيف تتغير قيمة الـ”loss” بين الـ”epochs”. إذا كانت قيمة الـ”loss” تقل، فإن ذلك يعني أن النموذج يتعلم بشكل أفضل ويصبح أداؤه أفضل. وعلى العكس، إذا زادت قيمة الـ”loss”، فإن ذلك يشير إلى أن النموذج يحتاج إلى ضبط أو تحسين.
هذه العملية تستمر حتى يتم الوصول إلى عدد محدد من الـ”epochs” أو حتى يتم الوصول إلى أداء يعتبر مقبولاً. يجب مراقبة هذه القيم لضمان أن النموذج يتعلم بشكل جيد وأنه لا يعاني من مشاكل مثل التدريب الزائد أو التدريب الغير كافي.
إذا كان لديك أي استفسار إضافي حول هذا الموضوع أو حول استخدام Keras بشكل عام، فلا تتردد في طرح المزيد من الأسئلة.
المزيد من المعلومات

بالطبع، دعونا نعمق أكثر في مفهومي “epoch” و”loss” ونلقي نظرة على كيفية تحسين أداء النموذج في Keras.
1. فهم الـ”Epoch” بشكل أعمق:
الـ”epoch” هو دورة كاملة لتمرير جميع البيانات التدريبية عبر النموذج. في كل “epoch”، يتم تحديث الوزن والتشغيل (الـparameters) للنموذج بناءً على الفروق بين الإخراج المتوقع والإخراج الفعلي. هذا يسمح للنموذج بتعلم التفاصيل والأنماط في البيانات التدريبية.
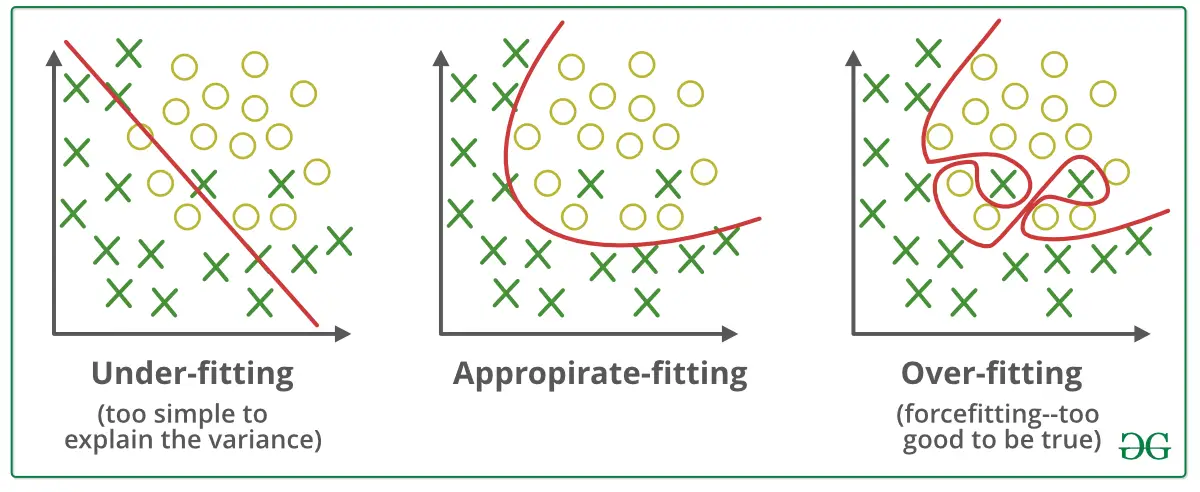
من المهم فهم كم “epoch” يكون مناسبًا لمجموعة بيانات محددة. إذا كنت تستخدم عددًا قليلاً جدًا من “epochs”، قد لا يكون للنموذج الوقت الكافي لتعلم الأنماط بشكل كامل. ومن ناحية أخرى، إذا كان العدد كبيرًا جدًا، يمكن أن يؤدي ذلك إلى التدريب الزائد (overfitting).
2. فهم الـ”Loss” (الخسارة):
الـ”loss” هو مقياس لمقدار الخطأ بين الإخراج المتوقع والإخراج الفعلي للنموذج. يتم استخدام دوال الخسارة مثل MSE (Mean Squared Error) أو Categorical Crossentropy لقياس هذا الخطأ. هدف التدريب هو تقليل قيمة الـ”loss” لضمان أداء أفضل.
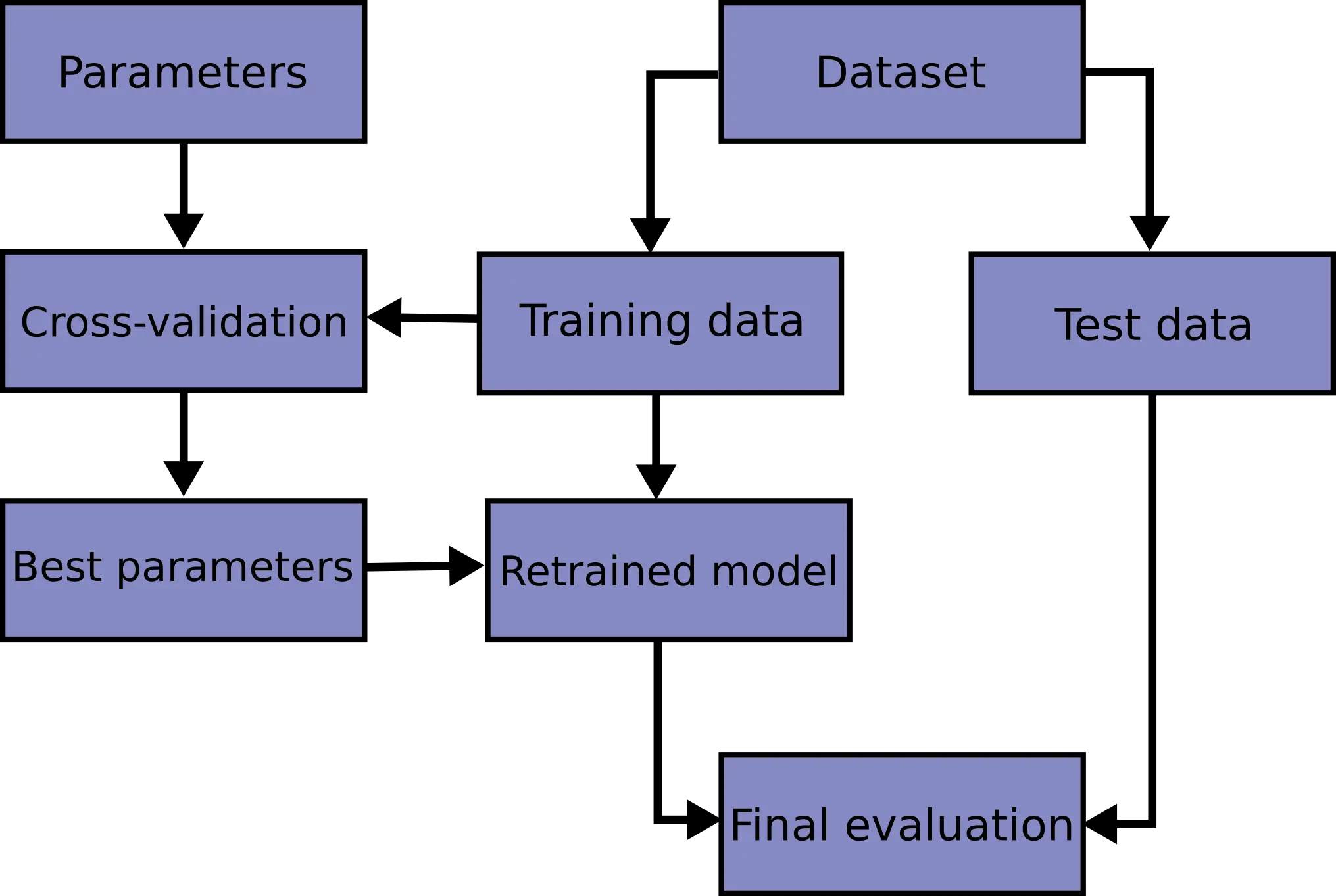
لتحسين الـ”loss”، يمكن استخدام تقنيات مثل تعديل معدل التعلم (learning rate)، تحسين الخوارزمية، أو إجراء تعديلات على هيكل النموذج. أيضًا، يمكن تقسيم بيانات التدريب إلى مجموعات التدريب والتحقق لتقييم أداء النموذج بين الـ”epochs” وتجنب التدريب الزائد.
3. ضبط الهيكل النموذجي:
قد يؤثر تصميم النموذج بشكل كبير على أدائه. يمكنك استخدام طبقات (layers) متعددة، تغيير عدد الوحدات في كل طبقة، أو إضافة طبقات جديدة لتحسين الأداء. يجب تحديد هيكل يناسب نوعية البيانات التي تعمل عليها.
4. التحسين والتقييم:
بعد التدريب، يتم تقييم أداء النموذج باستخدام بيانات التحقق. إذا كان الأداء جيدًا على بيانات التحقق، فهذا يشير إلى أن النموذج قادر على التعامل مع بيانات غير معروفة بشكل جيد.
في الختام، يجب على المستخدمين الجدد في Keras فهم الـ”epoch” والـ”loss” كجزء أساسي من عملية تدريب النموذج. التجربة والتعديل على النموذج يساعد في تحسين أدائه بمرور الوقت.