في هذا الشيفرة البرمجية بلغة البرمجة C، يتم تعريف هيكل بيانات باسم test يحتوي على ثلاثة أعضاء: x من نوع unsigned int، y من نوع long int، و z من نوع unsigned int أيضًا. في الدالة main(), يتم إنشاء متغير من نوع test يسمى t.
ثم يتم إنشاء مؤشرين إلى unsigned int يسمون ptr1 و ptr2 يشيران إلى العناصر x و z على التوالي في هيكل البيانات t. يتم طباعة الفارق بين قيمتي هذين المؤشرين باستخدام printf.
لفهم الإجابة والشرح بشكل صحيح، يجب أن نتعمق في كيفية تخزين هيكل البيانات في الذاكرة. يتم تخزين الأعضاء في ترتيب طبيعي في الذاكرة بناءً على نوع البيانات وحسب الترتيب الذي تم تعريفه في الهيكل. في هذا السياق، يتم تخزين x أولاً، ثم y، وأخيرًا z.
المعاملات:
xهوunsigned int، لذا يتم تخزينه عادة بحجم 4 بايت.yهوlong int، لذا يتم تخزينه عادة بحجم 4 أو 8 بايت (يعتمد على نوع النظام).zهو أيضًاunsigned int، لذا يتم تخزينه بحجم 4 بايت.
لنفترض أن النظام الخاص بك يستخدم حجم 4 بايت لكل unsigned int و long int. بناءً على ذلك، سيكون إجمالي حجم الهيكل هو 4 + 4 + 4 = 12 بايت.
عندما تقوم بحساب ptr2 - ptr1، فإنه يقوم بحساب الفارق في عدد العناصر بين ptr2 و ptr1. نعلم أن كل عنصر في الهيكل يستغرق 4 بايت، لذا ptr2 - ptr1 سيكون 12 / 4 = 3.
بالتالي، ستكون الإجابة عن هذا البرنامج 3، وهي الفارق في عدد العناصر بين x و z في هيكل البيانات.
المزيد من المعلومات

تتيح لنا فهم أعمق لهذا الشيفرة البرمجية استعراض الطريقة التي يتم بها تخزين الهيكل في الذاكرة وكيف يحسب البرنامج الفارق بين ptr2 و ptr1.
في الذاكرة، يتم تخزين الهيكل test بترتيب متتابع، حيث تأتي x أولاً، تليها y، ثم z. لنفترض أن عنوان البداية لهيكل t هو 0x1000. إذاً:
&t.xيشير إلى عنوان0x1000.&t.yيشير إلى عنوان0x1004(لأنunsigned intيأخذ 4 بايت).&t.zيشير إلى عنوان0x1008.
عند طباعة الفارق بين ptr2 و ptr1 باستخدام printf("%d", ptr2 - ptr1);، يقوم البرنامج بحساب الفارق بين العناوين بالبايت. لدينا:
ptr2يشير إلى0x1008.ptr1يشير إلى0x1000.
الفارق بين هاتين العناوين هو 0x1008 - 0x1000 = 8 بايت. ونظرًا لأن كل عنصر في الهيكل يأخذ 4 بايت، فإن الفارق بالعناصر هو 8 / 4 = 2.
بناءً على ذلك، يكون الإجابة الصحيحة على الشيفرة البرمجية هي 2، وهي الفارق في عدد العناصر بين x و z في هيكل البيانات test.
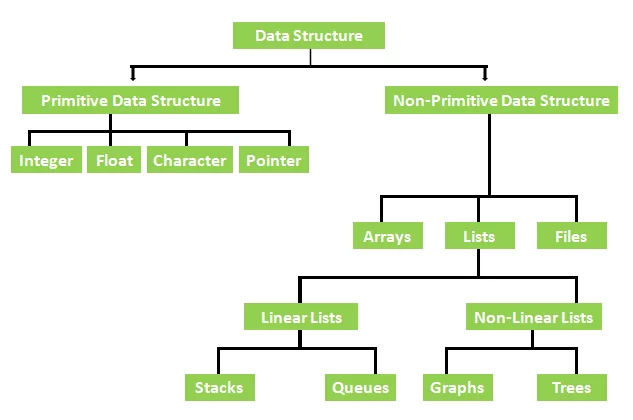
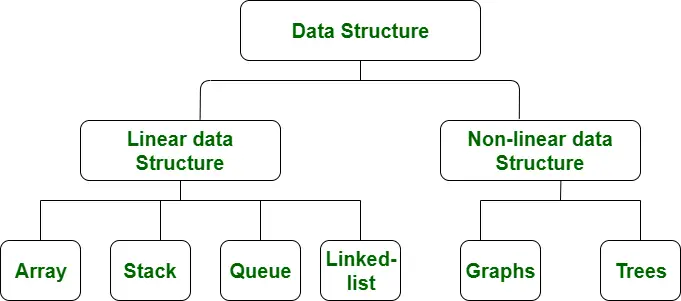
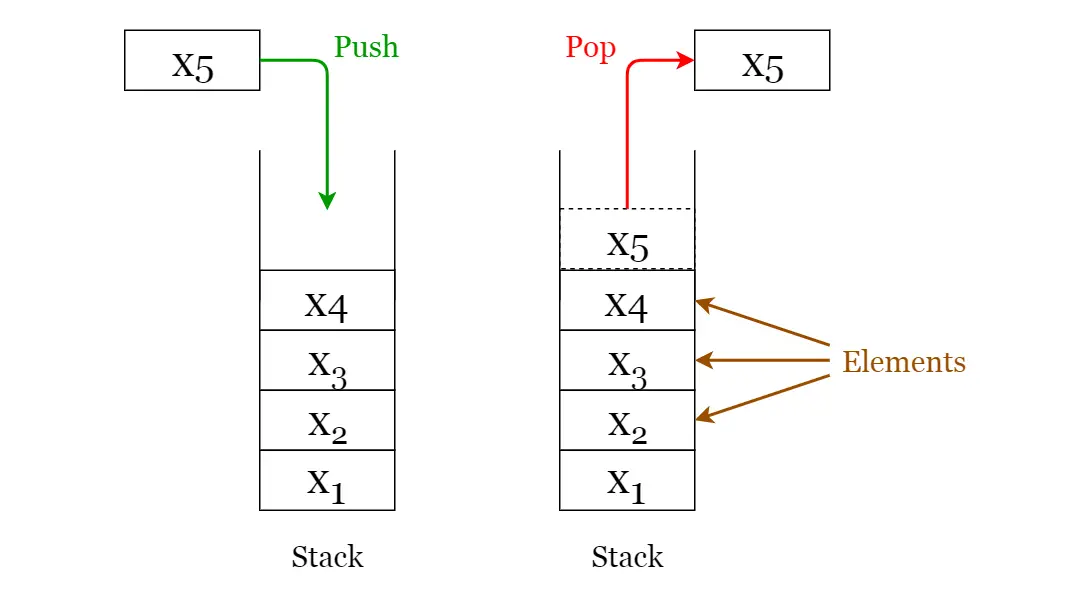
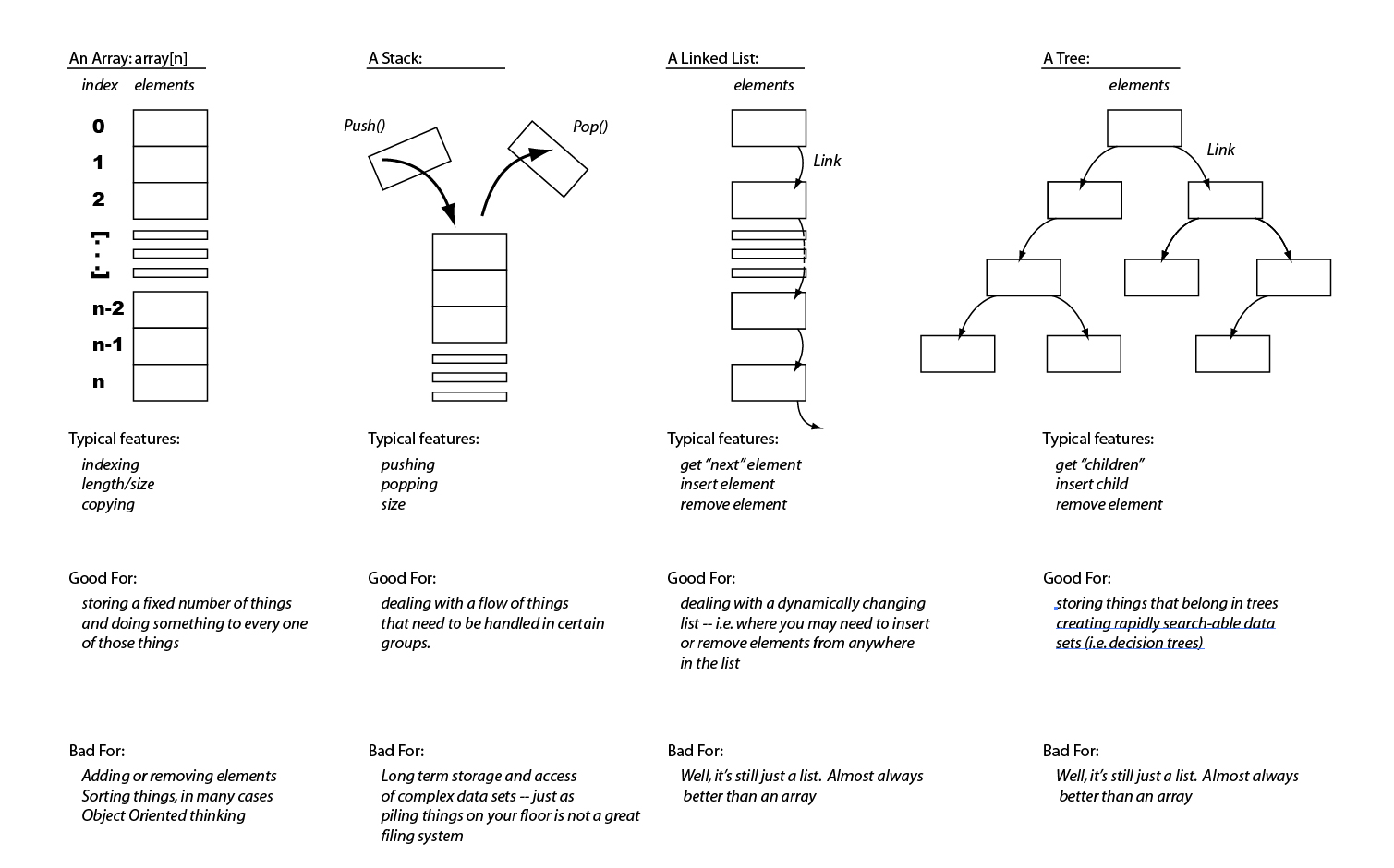
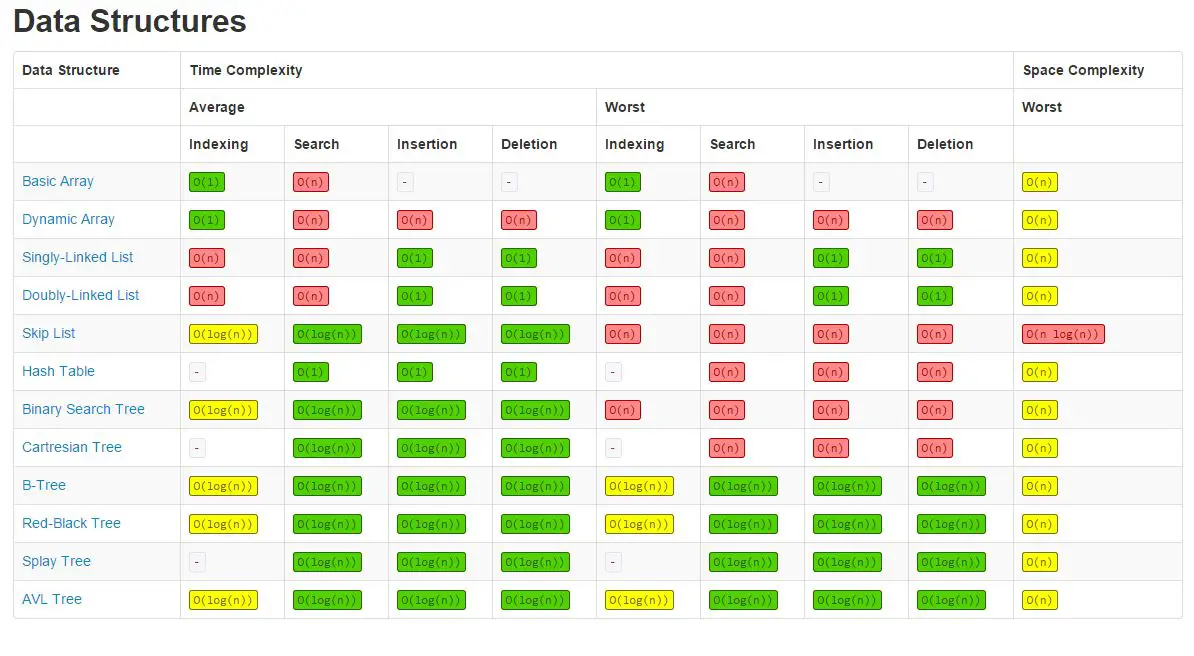 أمثلة على انواع هياكل البيانات المعقدة : Array – Linked List – Tree – Graph – Stack – Queue.
أمثلة على انواع هياكل البيانات المعقدة : Array – Linked List – Tree – Graph – Stack – Queue.